







Anyone who has spent hours trying to coax a spark of genuine emotion from a synthetic voice knows the frustration. You get a clean, perfectly pronounced track, but the critical emotional moments, like the excitement in a product launch or the empathy in a support message, often fall flat. They get stuck in an uncanny valley of lifeless perfection. For content creators, marketers, and developers, this has been a persistent creative roadblock. That roadblock is now being dismantled.
Table of Contents

StepFun AI has introduced Step-Audio-EditX, a revolutionary AI audio editing model that fundamentally reshapes our interaction with synthetic speech. Unlike traditional text-to-speech (TTS) systems that offer limited creative control, this next-generation tool treats audio manipulation with the same intuitive ease as editing text. This article provides a deep dive into Step-Audio-EditX, exploring its underlying technology, its superior performance against competitors, its significant market impact in the USA, and the practical strategies for leveraging this open-source AI audio model to pioneer the future of audio content.
The Core Concept: What is Step-Audio-EditX and Why Is It a Paradigm Shift?
The launch of StepFun AI Step-Audio-EditX marks a pivotal moment in TTS innovation. It moves beyond mere voice generation into the realm of true audio creation, offering a level of control that was previously unimaginable. This shift is not just an incremental improvement; it’s a complete redefinition of what’s possible with advanced voice synthesis in the USA.
Defining the Next Generation of AI Audio
At its heart, Step-Audio-EditX is a sophisticated 3B parameter audio LLM (Large Language Model). This distinguishes it from conventional TTS systems, which often operate as rigid, “black box” models where you input text and hope for a desirable output. Step-Audio-EditX dismantles this limitation entirely.

The core innovation lies in its ability to process audio manipulations as simple, token-level text operations. This means a user can instruct the model to make a sentence sound “more excited,” “a bit hesitant,” or “louder at the end” using natural language prompts. This is the key to achieving truly expressive audio editing, transforming a static process into a dynamic, creative dialogue between the user and the AI.
Why Open-Source Matters for the US Tech Ecosystem
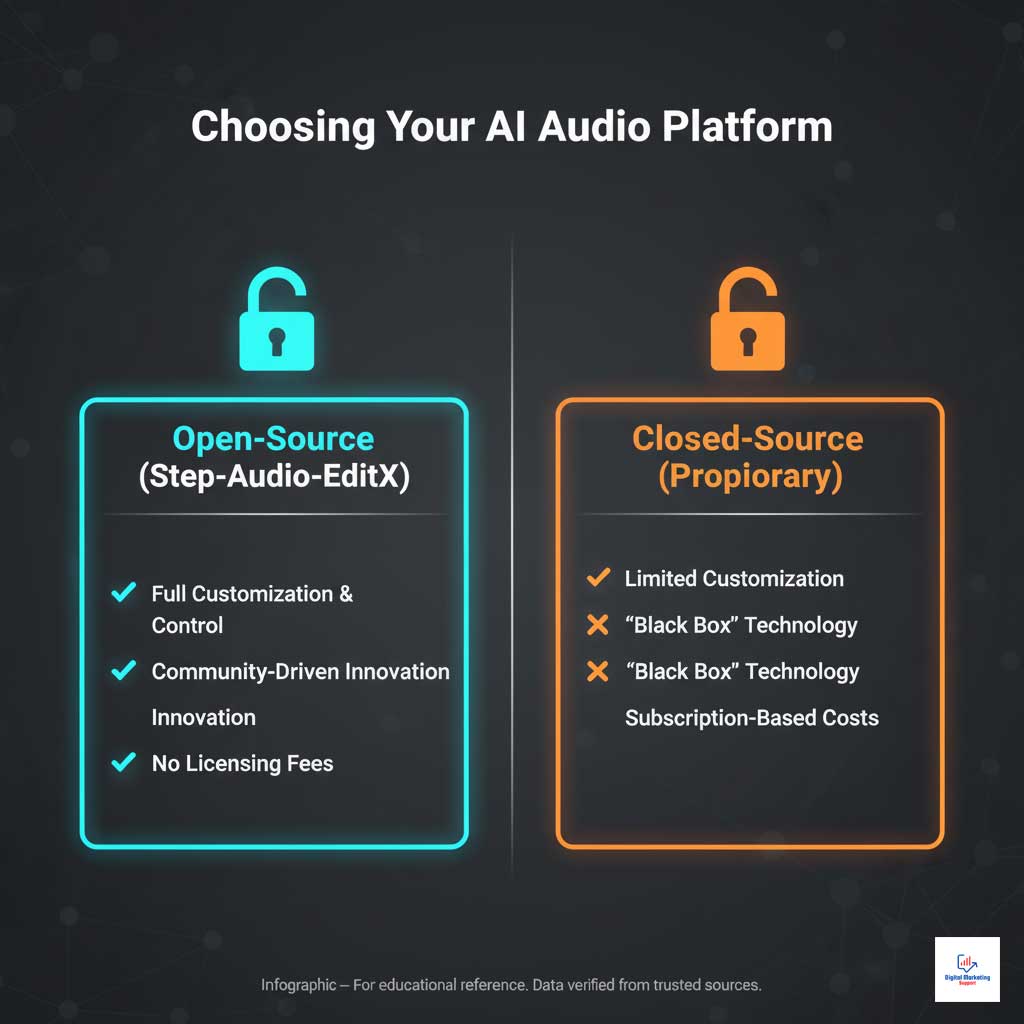
StepFun AI’s decision to release Step-Audio-EditX as an open-source AI audio model is a strategic move that will have a profound impact on the American tech landscape. By providing public access to the model’s code, weights, and benchmarks, the company is democratizing access to cutting-edge technology that was once the exclusive domain of large corporations.
This accessibility empowers small businesses, startups, and independent researchers across the USA to innovate without prohibitive licensing fees. It fosters a more vibrant and competitive market, accelerating voice AI development in the USA by providing a powerful, flexible foundation for building novel applications. This move is a catalyst for the next wave of generative AI audio tools.
Latest Industry Trends and Technical Insights: A Look Under the Hood
The superior capabilities of StepFun AI Step-Audio-EditX are not magic. They are the result of several groundbreaking technical innovations that represent the leading edge of AI audio processing trends in 2025. Understanding these components reveals why this AI audio editing model is setting a new industry standard.
The Dual Codebook Tokenizer: Capturing the Soul of Speech
The secret to the model’s nuanced control starts with its dual codebook tokenizer. This sophisticated component deconstructs speech into two distinct streams: a linguistic stream that captures the words being said, and a semantic stream that encodes the paralinguistic information, including the emotion, tone, rhythm, and style.

Think of it like sheet music. The linguistic stream represents the notes, while the semantic stream represents the performance instructions, such as crescendo, playfully, or somber. By separating these elements, Step-Audio-EditX can modify the performance without altering the words, enabling incredibly precise emotional speech synthesis.
Large Margin Synthetic Data: The Secret to Nuanced Control
Another key differentiator is the model’s training methodology. Instead of relying on overly complex architectural changes, Step-Audio-EditX was trained using “large margin synthetic data.” This involves feeding the model high-margin triplets and quadruplets, which are sets of audio that represent distinct points on an emotional or stylistic spectrum (e.g., neutral, slightly sad, very sad).
This technique teaches the model the subtle gradations between different expressions. It allows the audio LLM to understand not just what “happy” sounds like, but the vast range of happiness, from gentle contentment to pure elation. This is fundamental to its advanced paralinguistic audio control.

From Alignment to Output: The Role of PPO and BigVGANv2
To make the user experience intuitive, StepFun AI Step-Audio-EditX is fine-tuned using Supervised Fine-Tuning and Proximal Policy Optimization (PPO). These reinforcement learning techniques align the model’s behavior with natural language instructions, allowing it to understand and execute chat-style editing prompts accurately.
Once the desired audio is modeled internally, a state-of-the-art BigVGANv2 vocoder reconstructs the final, high-fidelity waveform. This last step ensures the output is not only emotionally resonant but also crisp, clear, and free of artifacts, solidifying its status as a premier tool for speech editing AI in 2025.
Benchmarking Dominance: How Step-Audio-EditX Stacks Up
A new technology’s true value is proven through objective performance metrics. StepFun AI has established the superiority of its AI audio editing model through a rigorous, unbiased evaluation process, demonstrating clear advantages over existing market leaders.
The Step-Audio-Edit-Test: An Unbiased Evaluation
To quantify its performance, StepFun AI developed the Step-Audio-Edit-Test benchmark. In a novel approach to evaluation, the company utilized Google’s Gemini 2.5 Pro as an impartial judge to assess the accuracy of emotion, style, and paralinguistic edits across both English and Chinese.

One of the most significant findings was the power of iterative audio editing AI. The benchmark revealed that the model’s accuracy in rendering the desired emotion and style progressively improves with each round of editing. A first edit might get 80% of the way there, but a second clarifying edit can push the accuracy to over 95%, a capability other generative AI audio tools lack.
Step-Audio-EditX vs. The Competition: A Comparative Analysis
When placed head-to-head against prominent models, Step-Audio-EditX demonstrates clear superiority in the areas that matter most for creative professionals. The table below offers a direct comparison, highlighting why this speech editing AI in 2025 is a game-changer.
| Feature | StepFun AI Step-Audio-EditX | MiniMax / Doubao Seed TTS | Leading Closed-Source Models (e.g., ElevenLabs) |
| Editing Control | Token-level, highly granular (emotion, style, prosody) | Primarily prompt-based with limited fine-tuning | High-quality generation, but post-editing is limited |
| Iterative Editing | Core feature; accuracy improves with each edit | Not designed for iterative refinement | Not applicable; requires re-generation from a new prompt |
| Open-Source | ✅ Yes (Code, weights, benchmarks) | ❌ No | ❌ No |
| Core Technology | 3B Audio LLM with dual codebook tokenizer | Standard Transformer-based TTS | Proprietary voice cloning and synthesis models |
| Key Advantage | Unmatched expressive control & customizability | High-quality voice generation for specific languages | Ease of use and realistic voice cloning |
| Best For | Developers, media firms, and creators needing precise control | General-purpose, high-quality voice generation | Quick voice cloning and straightforward narration |
This comparison makes it clear that while closed-source models offer excellent voice cloning and other TTS systems provide quality generation, StepFun AI Step-Audio-EditX is in a class of its own for creators who demand deep, iterative, and expressive audio editing.
Can Step-Audio-EditX Improve Closed-Source TTS Outputs?
Yes, and this is one of the model’s most powerful and versatile features. Step-Audio-EditX exhibits remarkable generalization capabilities, allowing it to function as a post-processing enhancement tool. Users can take audio generated by any closed-source TTS system, feed it into Step-Audio-EditX, and use its fine-grained controls to add the emotional depth and stylistic nuance the original output was missing. This makes the audio LLM a valuable asset even for workflows that rely on other platforms.
Practical Strategies and Real-World Impact on US Industries
The arrival of a tool this powerful heralds a new era for content creators and industries across the United States. From media and marketing to healthcare and automotive, the applications for this AI audio editing model are vast and transformative, directly influencing top AI trends in American audio production 2025.
A New Playbook for Digital Content Creation with AI
Media companies and publishers now have a new set of strategies to create higher-quality content faster and more efficiently.
- Next-Generation AI Voice Dubbing Solutions: Studios can slash localization timelines and costs for films and series. Instead of weeks of re-recording, they can use StepFun AI Step-Audio-EditX to adjust the emotional tone and timing of translated audio to perfectly match the on-screen performance.
- Automated and Expressive Audiobook Narration: Publishers can produce entire audiobooks with a single voice that maintains perfect emotional consistency. The model can be instructed to read suspenseful chapters with a tense whisper or joyful moments with an uplifted tone, creating a far more engaging experience for listeners. This is a significant leap in digital content creation AI.
Top AI Trends in American Audio Production 2025: Marketing and Advertising
For marketers, emotional speech synthesis is a powerful tool for building brand affinity and driving conversions. The best use cases for an audio LLM in marketing and media revolve around personalization and optimization.

A prime example is A/B testing ad creatives. A marketer can take a single voice-over script and, using StepFun AI Step-Audio-EditX, generate multiple versions. One could sound energetic and urgent for a flash sale, another warm and reassuring for a brand-building campaign, and a third calm and authoritative for a product tutorial. This allows for data-driven optimization of audio content at a scale never before possible.
Industry Use Case Deep Dive
The impact of this open-source AI audio model extends far beyond media. The following table outlines key applications across sectors that are central to audio AI adoption in the USA.
| Industry Vertical | Use Case | Key Step-Audio-EditX Feature Used | Expected Business Outcome |
| Media & Entertainment | High-speed, emotionally accurate film dubbing | Iterative emotional editing, paralinguistic control | Faster time-to-market for global releases, higher audience immersion |
| Gaming | Dynamic, adaptive NPC dialogue | Zero-shot TTS, real-time style modulation | More realistic and engaging game worlds, reduced voice actor costs |
| Marketing & Advertising | A/B testing ad creatives with different emotional tones | Fine-grained emotional speech synthesis | Increased conversion rates, better brand-message alignment |
| Healthcare | Creating empathetic virtual assistants for patient communication | Paralinguistic audio control (e.g., calming tone, pauses) | Improved patient experience, better adherence to instructions |
| Automotive | Developing next-gen, conversational in-car assistants | Expressive audio editing for natural responses | Enhanced driver safety and user satisfaction |
| Consumer Electronics | Building more natural and helpful smart home devices | Dual codebook tokenizer for prosody preservation | Higher product adoption rates and brand loyalty |
The Financial Angle: AI Audio Investment and Market Growth
The technological breakthroughs of Step-Audio-EditX are mirrored by strong economic indicators for the AI audio sector, particularly in North America. Investors and market analysts see this field as a key driver of future growth.
Growth Forecast for AI Audio Software by 2029 in the USA
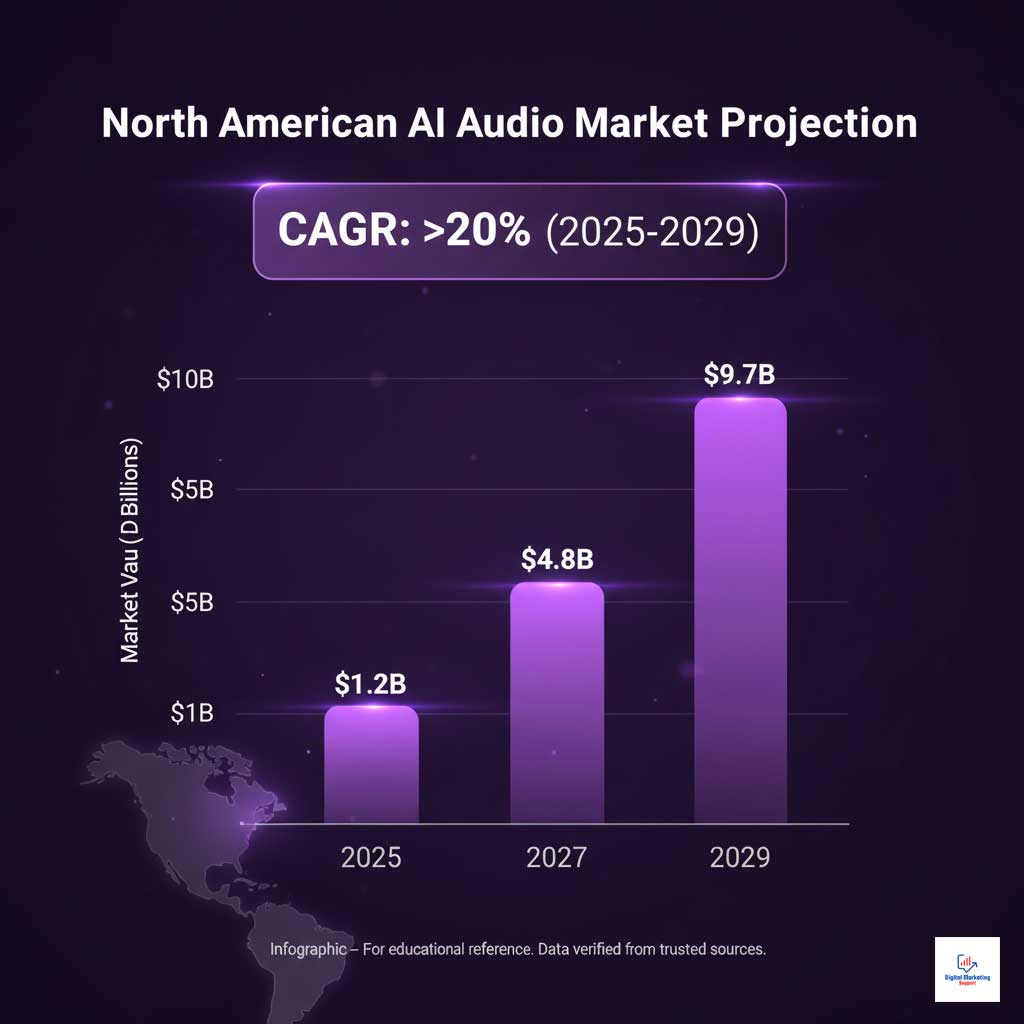
The North America AI audio software market is poised for explosive growth. Market analyses project a compound annual growth rate (CAGR) of over 20% for the AI-generated audio and voice synthesis market through 2029. This trajectory is fueled by increasing demand for advanced voice synthesis in the USA across sectors like entertainment, automotive, and healthcare. Open-source platforms are expected to be major contributors to this expansion, as they lower barriers to entry and spur widespread innovation.
Why Venture Capital AI Audio Investments Remain Resilient
Despite fluctuations in the broader tech market, venture capital AI audio investments in the United States remain robust. Investors are drawn to the tangible applications and clear ROI of technologies like StepFun AI Step-Audio-EditX. The open-source nature of the model is particularly attractive, as it de-risks investment by providing a proven, powerful platform upon which a multitude of startups can build new products and services. This creates a fertile ground for innovation and significant financial returns.
Summary & Key Takeaways: The Future is Expressive
The release of StepFun AI Step-Audio-EditX represents a fundamental shift in our relationship with digital audio. We are moving beyond the era of simple voice generation and into a new age of expressive audio creation. This powerful AI audio editing model offers a combination of granular control, open-source accessibility, and benchmark-proven performance that sets a new standard for the industry.
For creators, developers, and businesses across the USA, this technology unlocks the ability to craft deeply immersive, emotionally resonant audio experiences at unprecedented speed and scale. As one of the most significant audio research breakthroughs of the decade, Step-Audio-EditX is not just a new tool; it’s a catalyst for the next generation of digital content.
Frequently Asked Questions (FAQs)
What is Step-Audio-EditX in simple terms?
Step-Audio-EditX is an advanced, open-source AI tool that lets you edit the emotion, style, and tone of speech as easily as you edit text. It’s designed for creators who need precise control over how audio sounds and feels.
How is this different from AI voice changers or basic TTS?
While basic TTS converts text to speech and voice changers alter pitch, Step-Audio-EditX is an audio LLM that allows for deep, iterative editing of emotional and paralinguistic qualities. It’s about crafting a performance, not just generating a voice.
Is this AI audio editing model accessible for small businesses in the USA?
Absolutely. Because it is an open-source AI audio model, it is free for businesses of all sizes to use and build upon. This accessibility is one of its key advantages, democratizing advanced voice synthesis in the USA.
What are the best use cases for an audio LLM in marketing and media?
The best use cases include creating emotionally targeted ad campaigns, producing high-quality and expressive audiobook narration at scale, and developing dynamic, emotionally aligned voice-overs for films and video games.
How is AI reshaping global media content creation with tools like this?
Tools like Step-Audio-EditX are drastically reducing the time and cost of high-quality audio production, particularly for localization and dubbing. This allows media companies to reach global audiences faster and with more culturally and emotionally resonant content.
Can Step-Audio-EditX improve outputs from other TTS tools like ElevenLabs?
Yes. It can be used as a post-processing tool to add nuanced emotion and style to audio generated by other closed-source TTS systems, effectively enhancing their output.
What are the benefits of emotion editing with AI models in 2025?
The main benefits are creating more engaging user experiences, building stronger emotional connections in marketing, and developing more natural and empathetic virtual assistants. These improvements lead to higher user satisfaction and conversion rates.
Will AI audio models threaten traditional audio production jobs?
While this speech editing AI in 2025 will automate certain tasks, it is more likely to evolve roles than eliminate them. It will function as a powerful collaborative tool, freeing audio professionals to focus on higher-level creative direction and artistry.
What are the regulatory challenges for AI audio in healthcare and automotive?
In these sectors, challenges include ensuring HIPAA compliance and data privacy in healthcare applications, as well as guaranteeing the reliability and safety of voice-based controls in automotive systems.
What programming knowledge is needed to use this open-source model?
A foundational understanding of Python and experience with machine learning frameworks like PyTorch are beneficial for developers looking to integrate or customize the StepFun AI Step-Audio-EditX model.
How does the “iterative editing” feature actually work?
Iterative editing allows you to refine an audio clip in multiple steps. You can make an initial edit, listen to the result, and then provide a follow-up prompt, like “make it a little more upbeat,” to fine-tune the performance until it’s perfect.
What is the growth forecast for the AI audio software market in the USA?
The growth forecast for AI audio software by 2029 in the USA is extremely positive, with market analysts projecting a CAGR of over 20%, driven by high demand across the media, entertainment, consumer electronics, and automotive industries.