








Citation SEO is the strategic process of optimizing content to be retrieved, synthesized, and attributed by Large Language Models (LLMs) like SearchGPT, Perplexity, and Google Gemini. Unlike traditional SEO which focuses on ranking blue links, Citation SEO focuses on Generative Engine Optimization (GEO) techniques. These include increasing Information Gain, structuring data with Semantic Triples, and establishing Entity Authority. The goal is simple. You want the AI to answer a user’s query by citing your brand as the primary source of truth.
Key Statistics: The Shift to Answer Engines
- 40% Visibility Boost: Authoritative, quote-heavy content sees a 40% increase in visibility within generative engines (Princeton & Georgia Tech GEO Study).
- Zero-Click Reality: By 2026, Gartner predicts search engine volume will drop by 25% due to AI chatbots and virtual agents.
- Citation Probability: Content with high “Information Gain” scores is 3x more likely to be cited than consensus-based content.
- Verification Layer: Perplexity AI and SearchGPT prioritize sources with valid Schema markup and academic citations over general blogs.
- Retrieval Speed: Vector search retrieves contextually relevant “chunks” in milliseconds based on semantic proximity, not just keyword matching.
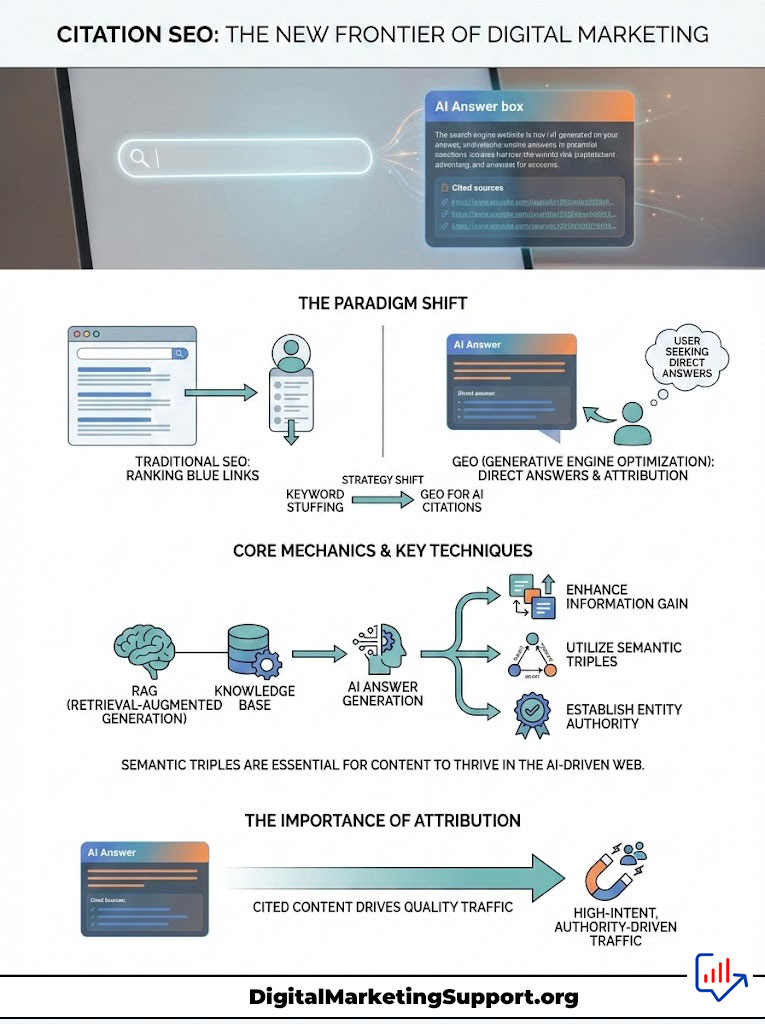
The era of chasing ten blue links is closing. We are witnessing a fundamental architectural shift in how information is retrieved online. Users are no longer searching for a list of websites. They are searching for answers. The interface has changed from a directory to a conversation.
Table of Contents
In this new ecosystem, your goal is no longer just to rank. It is to be attributed. If an AI answers a user’s question without citing you, you lose the traffic. If it cites you, you gain high-intent, authority-driven traffic that converts.
This article details how to get AI to cite your blog by pivoting your strategy from keyword stuffing to Generative Engine Optimization (GEO). We will explore the mechanics of Retrieval-Augmented Generation (RAG). We will discuss the importance of Information Gain. Finally, we will cover the technical necessity of Semantic Triples to ensure your content survives the transition to the AI web.
Understanding the Mechanics: How LLMs Choose Sources
Before executing a strategy for Citation SEO, one must understand the machine governing the output. Traditional search engines use an inverted index to map keywords to documents. Large Language Models (LLMs) operating as search engines use a different architecture known as Retrieval-Augmented Generation (RAG).
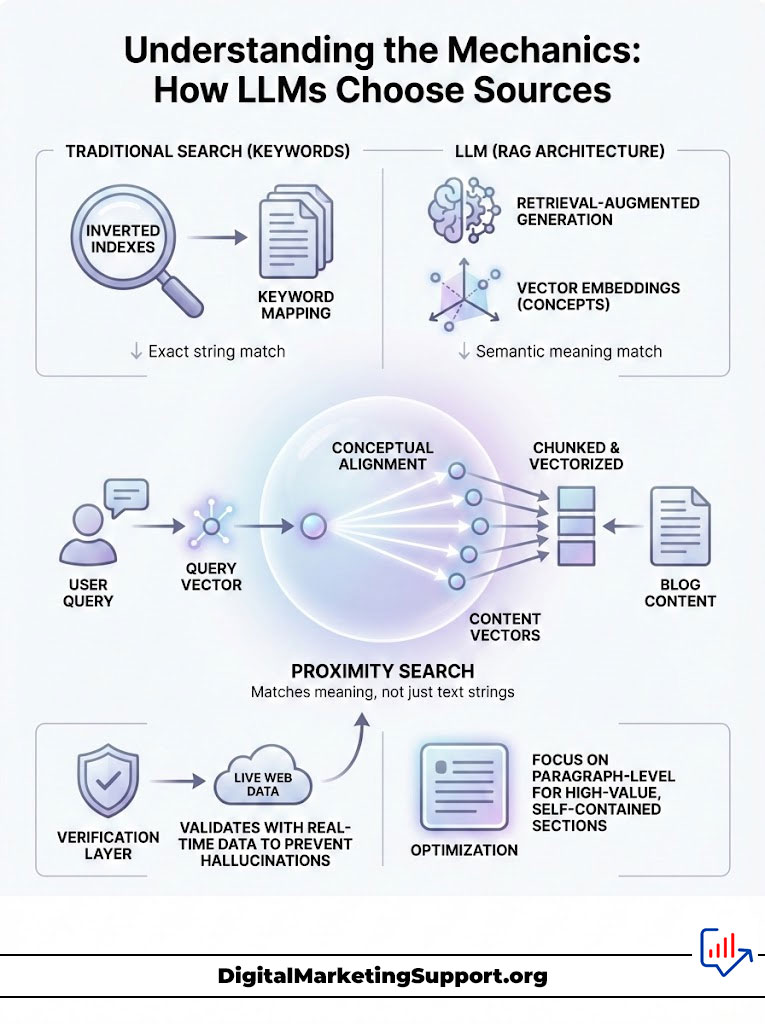
You need to stop thinking like a librarian and start thinking like a data scientist. The old way involved matching a string of text to a database entry. The new way involves matching concepts in a mathematical space.
Vector Embeddings and Proximity Search
When a user asks a question, the engine does not simply look for matching words. It converts the user’s query into a “vector embedding.” This is a long string of numbers representing the semantic meaning of the request.
Simultaneously, your blog content is broken down into chunks and converted into similar vectors. The search process is a mathematical calculation of “proximity.” The AI looks for content vectors that are mathematically closest to the query vector in a multi-dimensional space.
This means your content must be conceptually aligned with the answer. It cannot just be textually aligned with the keyword. If you write about “apple” in the context of fruit, your vector is different than “Apple” in the context of technology. The AI knows the difference instantly.
The Trust Layer and Verification
Models like SearchGPT and Perplexity apply a “verification layer” to prevent hallucinations. They do not trust their internal training data for real-time facts. They reach out to the live web to ground their responses.
This is where Citation SEO becomes critical. The model retrieves external data to validate its answer. If your content provides the most “grounded” and structured data, the model attributes the answer to you. Google DeepMind’s research on “Attribution in Large Language Models” confirms that models are increasingly fine-tuned to prefer sources that provide verifiable evidence.
Expert Insight: The AI does not read your entire article at once. It retrieves “chunks” or passages. Therefore, optimization must happen at the paragraph level. You must ensure every section is self-contained and high-value.
Tip 1: Implement the GEO Framework (Generative Engine Optimization)
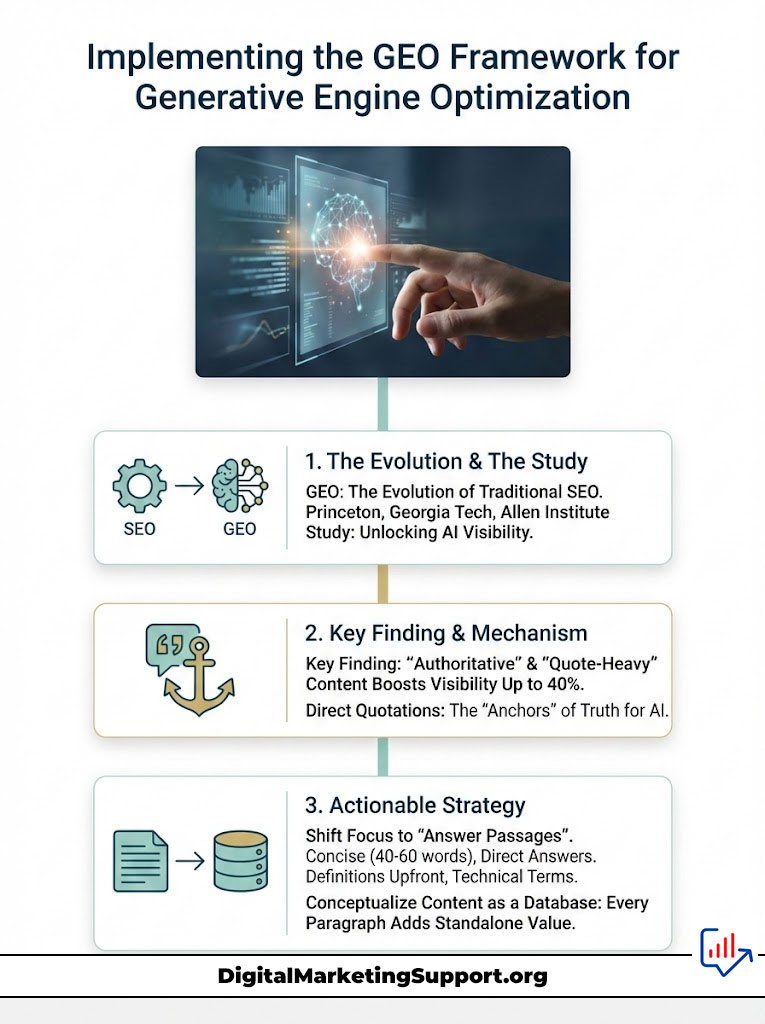
Generative Engine Optimization (GEO) is the successor to traditional SEO. It is the practice of tailoring content specifically for the retrieval patterns of generative AI. A landmark study by researchers from Princeton University, Georgia Tech, and the Allen Institute for AI defined the parameters of this new field. Their findings offer a roadmap for how to get AI to cite your blog.
The study was not just a theoretical exercise. It was a stress test of the current AI infrastructure. They fed thousands of queries into different engines and modified the source content to see what stuck. The results changed the industry.
The “Authoritative” and “Quote-Heavy” Shift
The GEO study tested various optimization methods to see which resulted in the highest visibility within AI responses. The results were definitive. Content that was modified to appear “authoritative” and “quote-heavy” outperformed other methods significantly.
Visibility improved by up to 40% when content included direct quotations from experts. It also improved when the content maintained a formal, authoritative tone. The AI views quotes as “anchors” of truth. It assumes that if you are quoting a known entity, your content is likely accurate.
Actionable Strategy: Passage Targeting
To implement the GEO framework, you must shift from targeting key phrases to targeting “answer passages.” An answer passage is a concise, 40-60 word block of text that directly answers a specific question within a broader article. This mimics the training data used by LLMs.
Here is how you do it. Do not bury the definition of a complex term in the middle of a paragraph. Place it at the very beginning of a section. Use technical terminology that aligns with the model’s training data. If you are writing about “Vector Search,” use terms like “high-dimensional space,” “cosine similarity,” and “embeddings.” This signals to the RAG system that your content is technically dense and relevant.
Think of your content as a database. Each paragraph is a row in that database. Is that row valuable enough to be retrieved on its own? If the answer is no, rewrite it.
Tip 2: Optimize for “Information Gain” and Uniqueness
Google holds a patent (US20200349181A1) regarding Information Gain scores. This concept is vital for Citation SEO. Large Language Models are predictive machines designed to reduce entropy (uncertainty). They prioritize sources that provide new information rather than repeating the consensus.

Imagine you are at a party. Five people tell you the exact same story about the weather. A sixth person tells you exactly why the weather pattern is shifting based on barometric pressure. Who do you listen to? The AI listens to the sixth person.
The “Sea of Sameness” Problem
In traditional SEO, the strategy was often to analyze the top 10 results and create a “Skyscraper” post that combined all their points. In the age of AI, this is a failed strategy. If your content merely summarizes what is already on the web, the AI has no reason to cite you.
It can generate that summary itself. To be cited, you must be the “outlier” that provides data the AI does not yet possess. You must provide the spark of novelty.
Practical Strategy: Proprietary Data
You must inject “high entropy” information into your content. This usually takes the form of proprietary data or original research. If you cannot conduct a massive study, you can still achieve high Information Gain.
Try curating unique datasets from public sources. Interview Subject Matter Experts (SMEs) for unique quotes. Take a contrarian perspective that challenges the consensus, provided you back it with logic. When an LLM scans the vector space, it identifies your content as a unique data point. This uniqueness forces the model to cite you as the origin of that specific insight.
Tip 3: Structure Content with Semantic Triples
LLMs do not understand text the way humans do. They understand relationships between entities. To optimize for this, you must structure your sentences using Semantic Triples. A semantic triple follows a strict structure: Subject – Predicate – Object.

This is the grammar of the machine. It is how knowledge graphs are built. If you deviate from this structure too often with flowery language, you confuse the parser. Simplicity is the ultimate sophistication in Citation SEO.
Why It Works
This structure mirrors how data is stored in a Knowledge Graph. Simple, declarative sentences are easier for an LLM to tokenize, parse, and store. For instance, the sentence “Citation SEO improves brand visibility” is a perfect triple. The Subject is “Citation SEO,” the Predicate is “improves,” and the Object is “brand visibility.”
Actionable Strategy: The BLUF Method
Audit your H2s and H3s. Ensure the first sentence of every paragraph uses the “Bottom Line Up Front” (BLUF) method. Do not lead with context. Lead with the fact. Context can follow later.
Bad Sentence Structure: “When we look at the changing nature of search, it is important to consider that Citation SEO is becoming a major factor for brands.”
Good Sentence Structure (Triple): “Citation SEO determines brand authority in generative search.”
The second sentence is machine-readable. It asserts a definitive relationship between entities. By writing in triples, you effectively “spoon-feed” the RAG system. This makes it significantly easier for the AI to extract and cite your claim.
Tip 4: Statistics-First Writing for Verification
LLMs are programmed for “Hallucination Mitigation.” This means they are terrified of being wrong. To protect themselves, they prioritize sources that provide “grounding” via verifiable statistics. A claim without a number is an opinion. A claim with a number is data.

If you say “website speed matters,” the AI treats it as a generic statement. If you say “website speed impacts conversion by 7% per second,” the AI treats it as a fact to be cited.
The Strategy: Grounding
Every major claim in your article must be backed by a number, a study, or a direct quote. This is non-negotiable for Citation SEO. When Perplexity or SearchGPT scans a document, they look for these “anchors” of truth.
Actionable Tips for Statistical Density
Avoid vague quantifiers. Do not use words like “many,” “several,” “most,” or “a lot.” Replace them with specific figures. Precision builds trust with both humans and machines.
- Instead of “Many users prefer AI,” write “68% of users prefer AI interfaces (Salesforce, 2024).”
- Instead of “It loads fast,” write “The page loads in 1.2 seconds.”
Furthermore, cite primary sources. Do not link to a blog that links to a blog that links to a study. Link directly to the PDF or the .gov report. Perplexity AI’s citation guidelines emphasize a preference for academic and primary sources. By positioning your blog as a node that connects directly to primary data, you inherit the authority of that data in the eyes of the LLM.
Tip 5: Leverage Schema and Knowledge Graphs
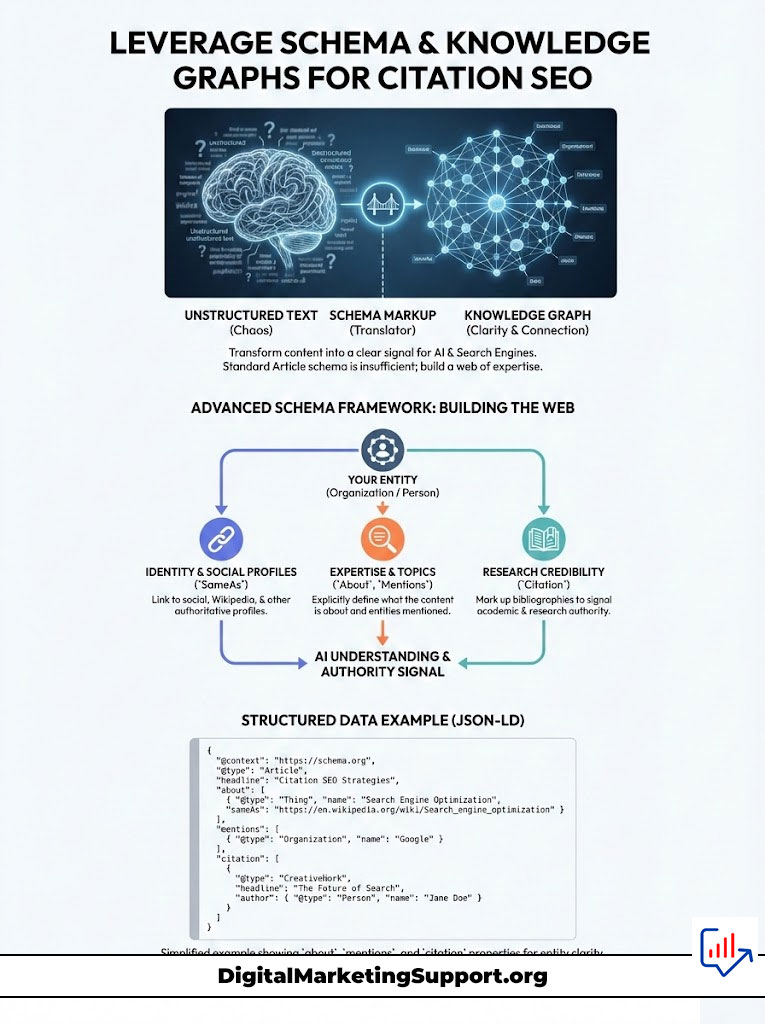
Your blog is unstructured text. Schema markup is the translator that turns that text into structured data that machines can parse instantly. For Citation SEO, standard schema is insufficient. You need to implement advanced schema that defines entities.
Most SEOs stop at basic Article schema. That is a mistake. You need to build a web of connections that explicitly tells the AI who you are and what you know.
Technical Implementation
You must use the `SameAs` property in your Organization schema. This property links your brand to your social profiles, Crunchbase listing, and Wikipedia page (if available). This solidifies your “Entity Authority” in the Knowledge Graph. It tells the AI, “This is not just a string of text; this is a recognized entity.”
Additionally, use `Mentions` and `About` schema in your Article markup. This explicitly tells the crawler what entities are present in your content. If you are writing about “Generative Engine Optimization,” tag it in the schema.
Citation Schema
You should also implement `Citation` schema to mark up your bibliography. This signals to the RAG system that your content is researched and grounded. Below is a conceptual example of how to structure this data for an article.
<script type=”application/ld+json”>
{
“@context”: “https://schema.org”,
“@type”: “Article”,
“headline”: “How to Get AI to Cite Your Blog”,
“about”: [
{ “@type”: “Thing”, “name”: “Citation SEO” },
{ “@type”: “Thing”, “name”: “Generative Engine Optimization” }
],
“citation”: [
{ “@type”: “CreativeWork”, “headline”: “Princeton GEO Study” },
{ “@type”: “CreativeWork”, “headline”: “Google Patent US20200349181A1” }
]
}
</script>
Tip 6: Target “N-Grams” and Co-Occurrence
To understand how to get AI to cite your blog, you must understand probability. LLMs predict the next word in a sequence based on probability derived from training data. This concept relies on N-grams (sequences of N words).

Think of it like autofill on steroids. If you type “Peanut butter and,” the model predicts “jelly.” Why? Because those words co-occur billions of times in the training data. You want your brand to be the “jelly” to your industry’s “peanut butter.”
Strategy: Brand Association
Your goal is to make your Brand Name statistically appear next to your Target Topic as frequently as possible. You want the probability of “Your Brand” appearing after “Topic X” to be high. This is achieved through co-occurrence.
Ensure consistent phrasing within your own content. If you have a proprietary framework, name it and use that name consistently. For example, use “Acme Corp’s Citation SEO Protocol” every time. Do not vary the name.
External Co-Occurrence
This extends to off-page SEO. When you secure guest posts or PR mentions, the value is no longer just the backlink. The value is the co-occurrence of your brand name in the same sentence as the keyword.
A brand like HubSpot became synonymous with “Inbound Marketing” through sheer co-occurrence volume. The model “learned” that these two N-grams belong together. You must replicate this density for your niche.
Tip 7: Platform Nuances (SearchGPT vs. Perplexity vs. Google)
Not all AI models are the same. A “Portfolio Approach” is required to satisfy different retrieval mechanisms. Citation SEO is not a one-size-fits-all solution; it requires nuance based on the target engine.
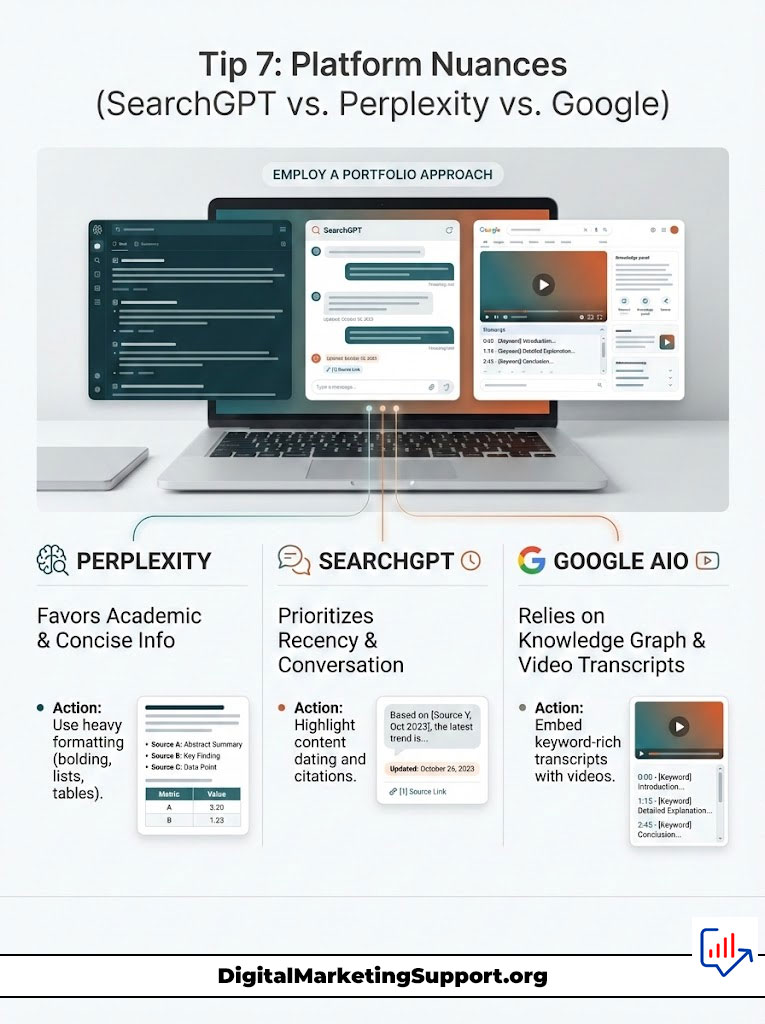
You wouldn’t use the same bait for a shark as you would for a trout. Similarly, you cannot treat SearchGPT the same way you treat Gemini. They have different appetites.
Perplexity AI
Perplexity favors “Pages,” academic papers, and direct answers. It has a high threshold for “fluff.” It will bypass a 2,000-word storytelling intro to find a bulleted list of facts.
To win here, use heavy formatting. Employ bolding, lists, and data tables. If you can summarize your entire argument in a table at the top of the post, do it.
SearchGPT
SearchGPT leans heavily on real-time news and established publisher partnerships. It values recency. Ensuring your content is dated correctly and cited by other news entities helps visibility here.
It also favors a more conversational, yet authoritative, tone compared to the academic rigidity of Perplexity. It wants to sound like a helpful assistant, not a university professor.
Google AIO (Gemini)
Google’s AI Overviews are heavily influenced by the existing Knowledge Graph and YouTube transcripts. Because Google owns the video ecosystem, embedding a video is crucial.
Include a clear, keyword-rich transcript with your embedded video. This can significantly boost your chances of being cited in a Gemini overview. Google trusts its own data sources above all else.
Comparative Analysis: SEO vs. GEO
For decision-makers allocating budget, it is vital to distinguish between traditional SEO and Generative Engine Optimization (GEO). The following table outlines the operational differences.
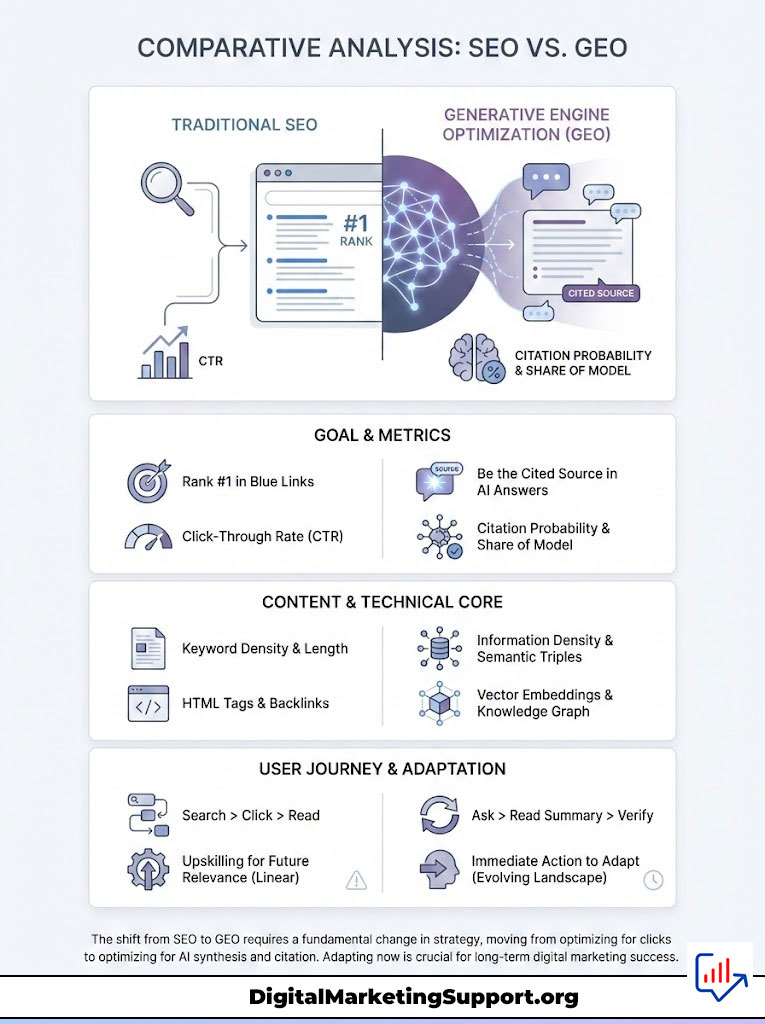
| Feature | Traditional SEO | Generative Engine Optimization (GEO) |
|---|---|---|
| Primary Goal | Rank #1 in Blue Links | Be the Cited Source in AI Answers |
| Success Metric | Click-Through Rate (CTR) | Citation Probability & Share of Model |
| Content Focus | Keyword Density & Length | Information Density & Semantic Triples |
| Technical Core | HTML Tags & Backlinks | Vector Embeddings & Knowledge Graph |
| User Journey | Linear (Search > Click > Read) | Synthesized (Ask > Read Summary > Verify) |
| Optimization | For the Crawler (Googlebot) | For the LLM (GPT-4, Gemini, Claude) |
The table above illustrates a stark reality. The skills that got you to page one in 2020 are not the skills that will get you cited in 2026. You need to upskill your team immediately.
The “Citation-Ready” Content Checklist
Before publishing, content editors should run their drafts through this rapid-fire checklist. This ensures Citation SEO compliance. Do not hit publish until you can check every box.

- Information Gain Check: Does this article contain at least one unique data point, contrarian view, or proprietary insight that exists nowhere else?
- Verification Check: Are all statistics specific (e.g., 47% vs. “almost half”) and cited to a primary source?
- Schema Validation: Is the JSON-LD schema valid, and does it include `mentions` and `citation` properties?
- Entity Clarity: Are the Subject-Predicate-Object relationships clear in the H2s and first sentences of paragraphs?
- Formatting Scan: Is the content chunked into answer passages? Are key terms bolded for emphasis?
Advanced Tactics: Writing for the Machine
Writing for RAG systems requires a stylistic departure from traditional “engaging” writing. The following table contrasts human-centric writing with machine-readable writing. You must find the balance.
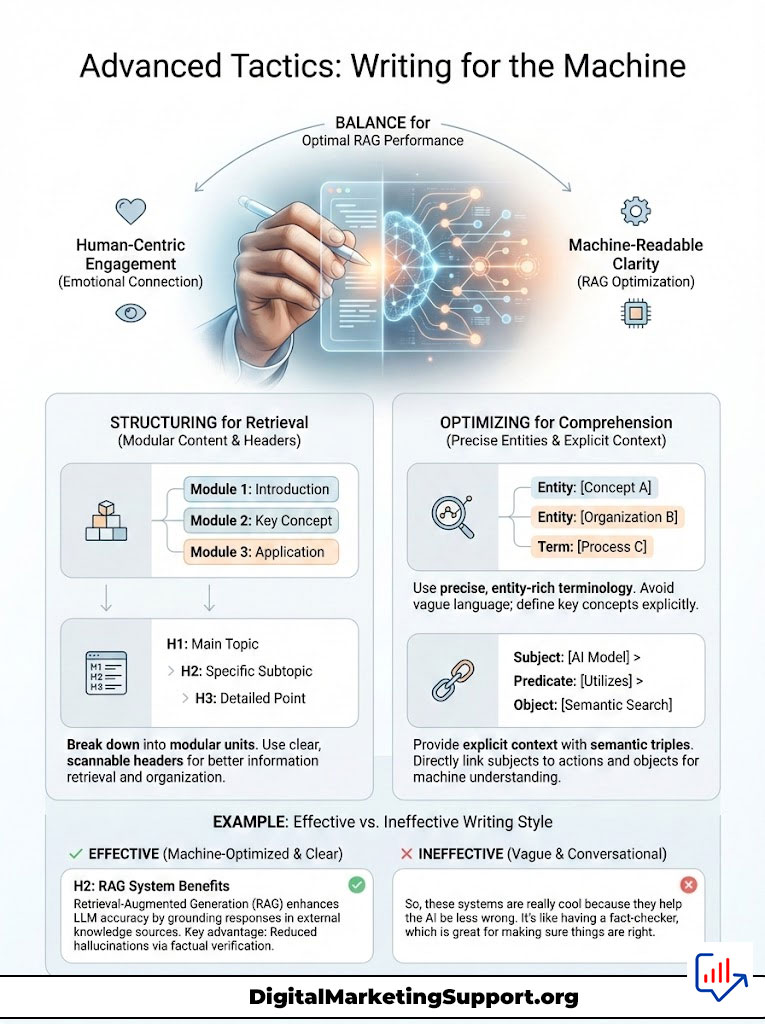
| Element | Human-Centric Writing | Machine-Readable Writing (RAG) |
|---|---|---|
| Headline | “Is AI the Future?” (Clickbait) | “AI Adoption Statistics and Future Projections” (Descriptive) |
| Structure | Narrative flow, storytelling | Modular, chunked content with clear headers |
| Vocab | Metaphors, slang, idioms | Precise, entity-rich terminology |
| Data | “Many people agree…” | “According to a 2024 Stanford study, 68% agree…” |
| Context | Implied through tone | Explicitly stated via Semantic Triples |
Building Your Citation Moat
The concept of a “moat” in business refers to a competitive advantage that is hard to replicate. In the age of AI, your moat is your proprietary data. It is the one thing the AI cannot generate on its own.
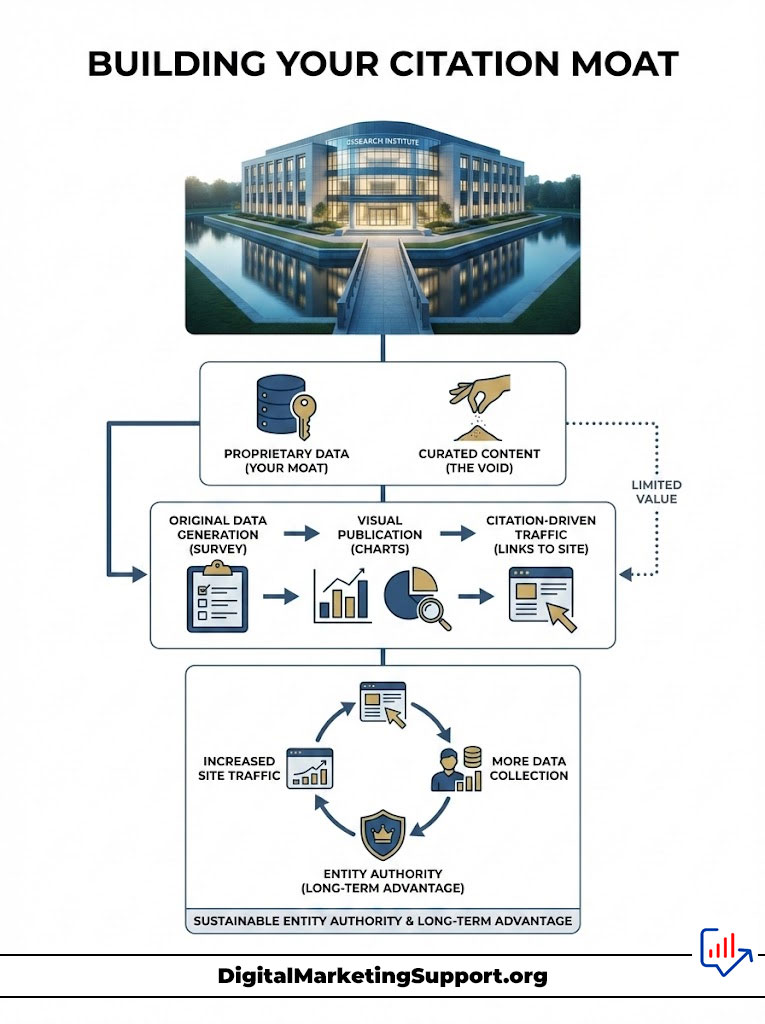
If you rely on curating other people’s content, you have no moat. The AI can curate faster than you. But if you generate the data that the AI needs to curate, you become indispensable.
The Feedback Loop
Start small. Conduct a survey of your email list. Publish the results with nice charts and a press release. Watch as the AI picks up on those unique statistics.
Once you are cited, you gain traffic. That traffic generates more data. You publish more studies. It is a virtuous cycle that builds Entity Authority over time.
Summary & Key Takeaways
Citation SEO is not a fad. It is the necessary evolution of search marketing in a world dominated by Large Language Models. As “Answer Engines” replace traditional search, the metric of success shifts from clicks to citations.
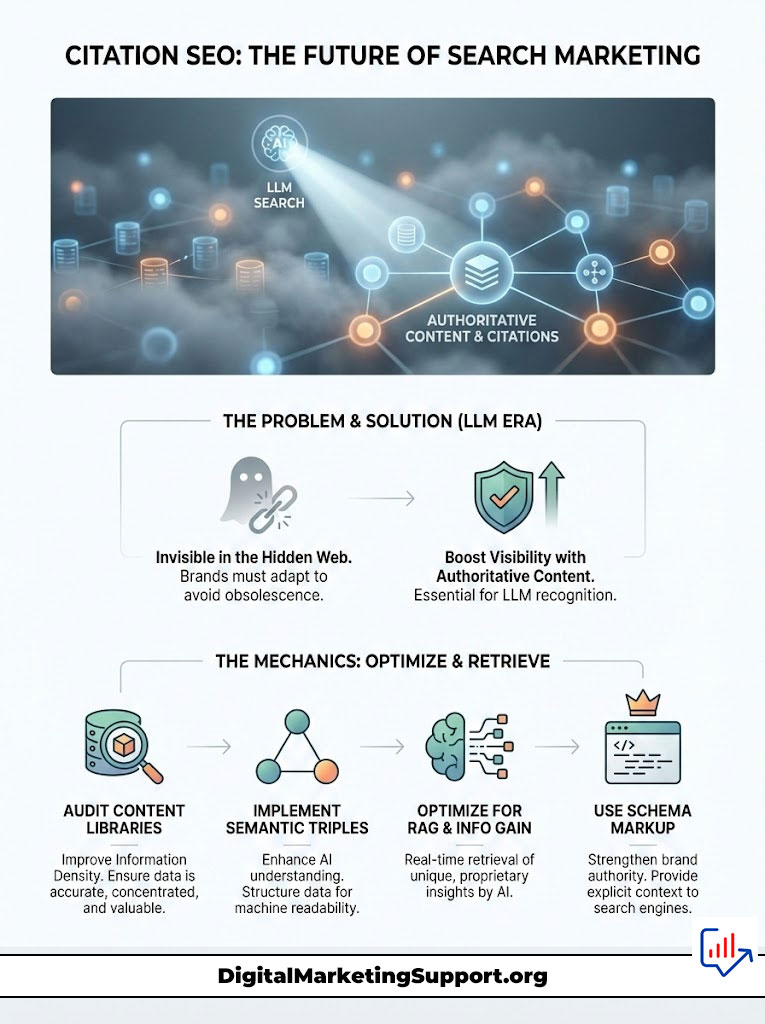
Brands that refuse to adapt to GEO standards risk disappearing into the “Hidden Web.” This is content that exists but is never retrieved because it lacks the structure and Information Gain required by the algorithm. You do not want to be invisible.
To secure your place in the AI future, you must audit your content library immediately. Focus on increasing Information Density. Implement Semantic Triples religiously. Verify every claim with hard data. The brands that master Retrieval-Augmented Generation optimization today will be the authorities cited by the AI assistants of tomorrow.
Frequently Asked Questions
What is Citation SEO and why is it important?
Citation SEO is the strategic optimization of content to ensure Large Language Models (LLMs) like SearchGPT and Gemini attribute your brand as the primary source of truth. As search evolves into a conversational interface, being the cited authority is the only way to drive high-intent traffic from AI-generated answers. Without specific citation optimization, your content may be synthesized by the AI without providing a link back to your website.
How does Generative Engine Optimization (GEO) differ from traditional SEO?
Traditional SEO focuses on keyword density and backlinks to rank in “blue link” directories, whereas GEO optimizes for the Retrieval-Augmented Generation (RAG) process used by AI. GEO prioritizes information density, semantic triples, and “Information Gain” to make content mathematically more likely to be retrieved by a vector search. Success in GEO is measured by citation probability and share of model response rather than just click-through rates.
What are Semantic Triples and how do they help AI understand my blog?
Semantic Triples are a machine-readable grammatical structure consisting of a Subject, Predicate, and Object (e.g., “Citation SEO improves brand authority”). By using this declarative structure, you align your content with how Knowledge Graphs and LLMs parse relationships between entities. This reduces “noise” for the AI parser, making it significantly easier for the model to extract and attribute your claims during the synthesis phase.
How can I increase the “Information Gain” score of my content?
To increase Information Gain, you must provide unique data points, proprietary research, or contrarian insights that do not exist in the current web consensus. LLMs are designed to reduce entropy, so they prioritize “high entropy” sources that offer new, verifiable information over generic summaries. Injecting original statistics and expert interviews ensures your blog remains a unique node in the AI’s retrieval space.
Why does Perplexity AI prioritize authoritative and quote-heavy content?
Perplexity AI uses a verification layer to mitigate hallucinations, seeking “anchors” of truth like direct expert quotes and academic citations. According to recent GEO studies, content modified to include authoritative language and direct quotations sees a 40% boost in visibility within generative engines. The AI views these elements as signals of reliability, making it more likely to cite the source as a grounded reference.
What is Retrieval-Augmented Generation (RAG) in the context of search?
RAG is the architectural framework where an LLM retrieves relevant “chunks” of data from the live web to inform its generated response. Instead of relying solely on its training data, the model queries external sources to provide real-time, accurate answers. For bloggers, this means your content must be optimized for “passage targeting” so that individual sections can be easily retrieved and synthesized by the AI.
How do vector embeddings impact which blogs get cited by AI?
Vector embeddings convert your text into numerical representations in a multi-dimensional mathematical space based on semantic meaning. When a user asks a query, the AI searches for content vectors with the highest “cosine similarity” or proximity to the query’s meaning. To get cited, your content must be conceptually aligned with the user’s intent rather than just matching specific keywords.
Which Schema markup types are most effective for Citation SEO?
Beyond standard Article schema, you should implement `mentions` and `about` properties to explicitly define the entities in your content. Using `citation` schema to list your own sources signals to the RAG system that your work is grounded in research. Additionally, Organization schema with the `sameAs` property helps solidify your brand’s Entity Authority within the global Knowledge Graph.
How can I optimize my blog specifically for Google’s AI Overviews (Gemini)?
Google’s Gemini relies heavily on the existing Google Knowledge Graph and often prioritizes video transcripts from YouTube. To increase your citation chances, embed relevant videos with keyword-rich transcripts and use the BLUF (Bottom Line Up Front) method for your introductory paragraphs. Google’s AI prefers structured data and clear, concise answers that can be easily displayed in a summarized snippet.
What role do N-grams and co-occurrence play in brand authority for AI?
LLMs predict the next word in a sequence based on the probability of word pairings, known as N-grams. By consistently using your brand name in close proximity to specific industry topics (co-occurrence), you train the model to associate your brand with that niche. Over time, the AI learns that your brand is a statistically probable “jelly” to the industry’s “peanut butter,” leading to higher citation frequency.
How do I implement “Statistics-First” writing for better AI retrieval?
Statistics-First writing involves replacing vague quantifiers like “many” or “most” with specific, verifiable figures (e.g., “68% of users”). This provides the “grounding” data that LLMs require to verify their answers and avoid hallucinations. Each major claim should be anchored by a number or a primary source link to make the passage more attractive for AI synthesis.
What is the “Citation Moat” and how do I build one?
A Citation Moat is a competitive advantage built on proprietary data that AI cannot generate or find elsewhere. By conducting original surveys, publishing case studies, or sharing unique datasets, you become an indispensable source for the AI. This creates a virtuous cycle where the AI must cite you to remain accurate, which in turn drives traffic and authority back to your brand.
Disclaimer
The information in this article is accurate to the best of our knowledge at the time of publication. Because the field of Generative Engine Optimization (GEO) and AI search is evolving rapidly, we recommend verifying technical implementations with the latest documentation from OpenAI, Google, and Perplexity.
References
- Princeton University & Georgia Tech – “GEO: Generative Engine Optimization” – Landmark study on visibility boosts for authoritative and quote-heavy content in AI engines.
- Gartner – “Gartner Predicts Search Engine Volume Will Drop 25% by 2026” – Statistical projection of the shift toward AI chatbots and virtual agents.
- Google Patents – US20200349181A1 – Official documentation regarding Information Gain scores and their role in content ranking.
- Google DeepMind – “Attribution in Large Language Models” – Research paper discussing how models are fine-tuned to prefer verifiable evidence and citations.
- Perplexity AI – “Perplexity Citation Guidelines” – Official resource detailing how the engine prioritizes academic and primary sources over general web content.
- Schema.org – “Article and Citation Properties” – Technical documentation for implementing structured data that AI models use for verification.
- Salesforce – “State of the Connected Customer” – Statistical source for user preferences regarding AI-driven search interfaces.