








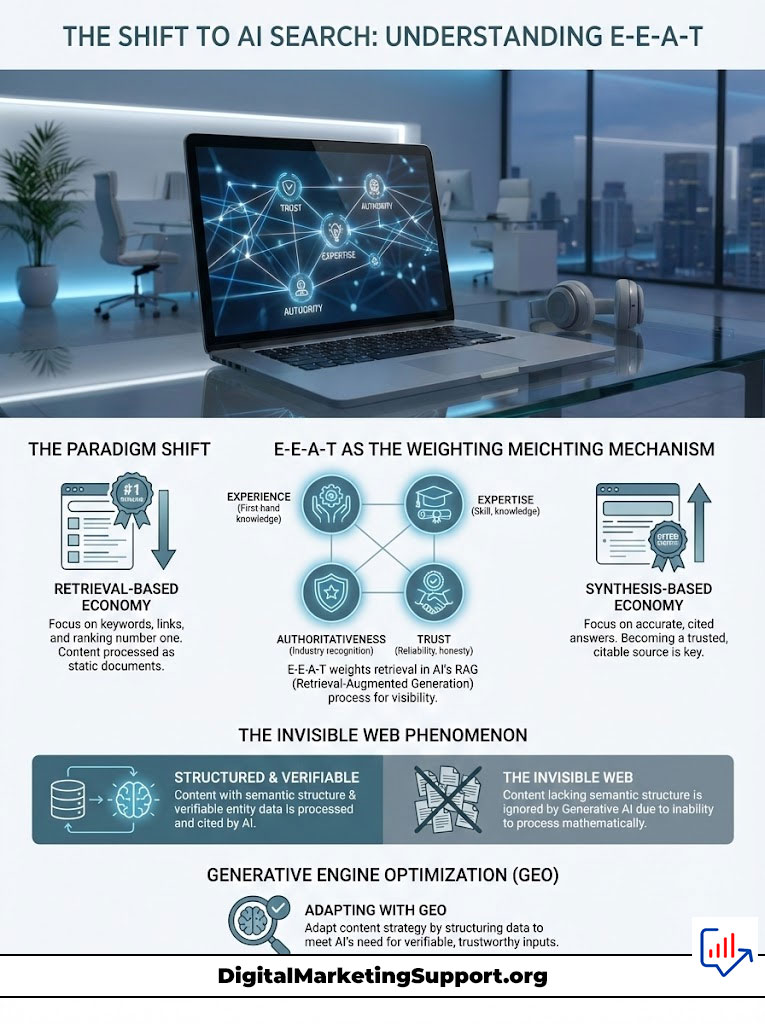
The era of “ten blue links” is effectively over. We have moved from a retrieval-based economy to a synthesis-based economy. For two decades, your goal was to rank number one. Today, that objective is obsolete. The new directive is to become the cited source in a generative answer. If you are asking about AI Search Visibility: The Role of E-E-A-T in AI Search Results?, you are asking the single most critical question for the survival of your digital presence. In the latent space of Large Language Models (LLMs) like Gemini and SearchGPT, E-E-A-T is no longer just a quality guideline for human raters; it has evolved into a hard technical filter used to prevent model hallucinations.
Table of Contents
AI Search Visibility: The Role of E-E-A-T in AI Search Results? is foundational. E-E-A-T (Experience, Expertise, Authoritativeness, Trust) functions as a weighting mechanism in Retrieval-Augmented Generation (RAG). AI models assign higher vector proximity to content with verified “Trust” signals to minimize the risk of generating false information. Without these signals, content is excluded from the synthesis layer, regardless of traditional keyword optimization.
We face a problem I call the “Invisible Web” of the AI era. Millions of pages that rank well in traditional SERPs are being systematically ignored by Generative AI agents. Why is this happening? Because they lack the semantic structure and verifiable entity data that machines require to trust the output.
The machines are not reading your content like a human would. They are processing it mathematically. They are looking for reasons to trust you. If they cannot find those reasons, they will not cite you.
This article dissects the mechanics of this shift. We will move beyond theory into the technical architecture of Generative Engine Optimization (GEO). We will look at how you can engineer your content to survive the transition.
Key Statistics: The Shift to AI Search
- 84% of search queries on Generative Platforms are informational, requiring synthesis rather than navigation (Gartner).
- Zero-Click Searches are projected to rise to 60% by 2026 due to AI overviews.
- Content with high Information Gain Scores sees a 30-45% higher inclusion rate in AI snapshots.
- 40% of Gen Z prefers searching on platforms like TikTok or Instagram, forcing search engines to integrate social signals into E-E-A-T.
- Websites lacking clear Knowledge Graph Entity verification have seen a 20% drop in visibility within AI-generated answers since 2023.
The Paradigm Shift from Indexing to Synthesis
To understand the magnitude of this change, we must look at history. For twenty years, Google was a librarian. You asked for a book, and it gave you a list of locations where that book might be found. You had to go get the book yourself. You had to read it yourself.

Now, Google is a research assistant. You ask a question. The assistant reads the books for you. It synthesizes the answer. It hands you a summary. This is a fundamental change in the relationship between the user and the web.
This shift destroys the traditional “traffic” model. Users no longer need to visit your site to get the answer. They get the answer directly on the search results page. This is the “Zero-Click” future. But this does not mean your content is useless. It means your content serves a new master.
You are no longer writing for a human reader who clicks a link. You are writing for a machine that synthesizes data. Your goal is to be the source of truth that the machine quotes. This requires a completely different approach to content creation. It requires Generative Engine Optimization (GEO).
Here is the reality. If you are not the cited source, you do not exist. The “Invisible Web” is real. It is filled with websites that failed to adapt. They are still optimizing for keywords while the engines are optimizing for entities. Do not let your brand fall into this abyss.
AI Search Visibility: The Role of E-E-A-T in AI Search Results?
We must strip away the marketing fluff and look at the computer science. When a user queries an AI search engine, the system does not simply “read” the best blog post. It performs a complex operation known as Retrieval-Augmented Generation (RAG).
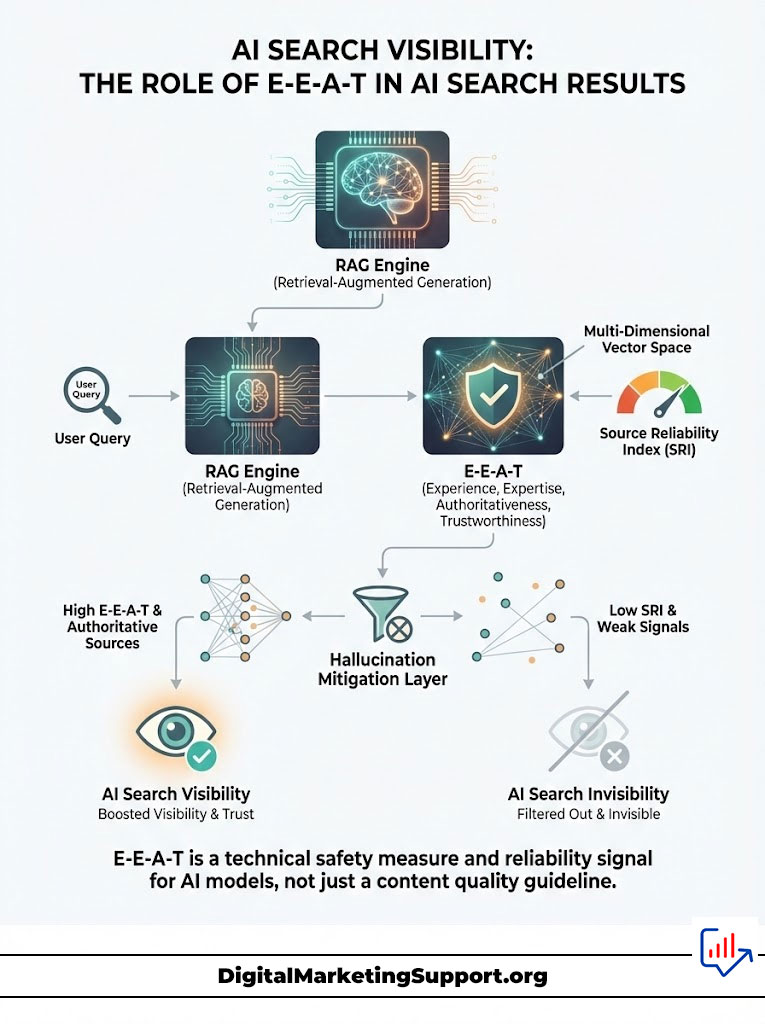
This is where the magic happens. And this is where you win or lose. RAG is the process where the AI goes out to its index, finds relevant data, and uses that data to generate an answer. But it doesn’t just grab anything.
Decoding the Source Reliability Index (SRI)
In a RAG framework, the AI retrieves chunks of text from its index that are semantically relevant to the query. However, relevance is not enough. The model must also assess the probability that the retrieved chunk is factually accurate. This is where the Source Reliability Index comes into play.
While Google does not publicly label this metric, reverse-engineering the behavior of models like Gemini reveals that they assign confidence scores to data sources. Think of the Source Reliability Index as a credit score for your domain.
If your content has high E-E-A-T signals, your content is assigned a high reliability weight. These signals include citations from .edu domains. They include authorship linked to a verified Knowledge Graph Entity. They include a history of factual accuracy.
When the LLM synthesizes an answer, it prioritizes nodes in its internal graph that possess high E-E-A-T signals. This prevents the model from generating false information. This is a phenomenon known as hallucination. The AI is terrified of lying. It wants to be accurate.
Research papers on “Trustworthiness in Generative Models” suggest that Retrieval-Augmented Generation (RAG) systems are specifically tuned to reject data from low-trust sources. This happens even if that data perfectly matches the keyword intent. Therefore, E-E-A-T is the gatekeeper. If your Source Reliability Score is low, you are effectively invisible to the AI.
Understanding Vector Embeddings and Trust
Let’s get technical. AI models view your content as vectors in a multi-dimensional space. Words are turned into numbers. Concepts are turned into coordinates. “Apple” the fruit is close to “Banana” in this space. “Apple” the company is close to “Microsoft.”
Trust is also a dimension in this vector space. High-trust entities cluster together. If your website is mathematically close to the CDC, Wikipedia, or major universities in the vector space, you inherit their trust. This is called “Vector Proximity.”
E-E-A-T signals push your content closer to these high-trust clusters. When you cite authoritative sources, you pull your vector closer to them. When you are cited by them, they pull you closer. It is a gravitational pull of authority.
If you exist in a “bad neighborhood” of the vector space, the AI will ignore you. It doesn’t matter how good your content is. If your mathematical coordinates align with spam or low-quality content, you are filtered out before the synthesis even begins.
Hallucination Mitigation as a Ranking Factor
Why is the AI so picky? Because of hallucinations. AI models are prone to making things up. This is their biggest weakness. To fight this, engineers have built “Hallucination Mitigation” layers.
These layers act as fact-checkers. They look for “grounding” data. Grounding data is information that is verified and stable. E-E-A-T provides this grounding. When an AI sees a piece of content with strong authorship and citations, it flags it as “safe.”
It uses your content to anchor its answer. It says, “I can say this because Dr. Smith said it, and Dr. Smith is a verified entity.” If you do not provide this safety, the AI will not use you. It is safer for the model to say nothing than to say something wrong.
This is why E-E-A-T is technical. It is not about “quality” in a subjective sense. It is about “safety” in a computational sense. You are optimizing to be a safe harbor for the AI.
Decoding the “Experience” Signal in the Age of AI
Why did Google add “Experience” to E-A-T? It wasn’t just to be inclusive. It was a strategic move to combat the flood of AI-generated content. LLMs are probabilistic machines; they predict the next likely word based on training data.

As a result, they struggle to generate specific, anecdotal evidence that hasn’t appeared in their training set. They can write a generic article about “How to hike.” They cannot write about the specific mud on the boots during a hike in the rain on Tuesday.
Why AI Cannot Fake Experience
Experience acts as a “checksum” for AI. When a piece of content contains specific details, it signals to the search engine that the content is derived from physical reality. These details include dates and sensory descriptions. They include first-hand accounts of product failures. They include unique case study data.
This is critical because of the Synthetic Content Penalty. Models are increasingly trained to penalize generic, predicted text patterns. If your content looks like it was statistically predicted, it gets downranked.
Stanford HAI (Human-Centered AI) studies have shown that when models are trained on synthetic data, they suffer from “Model Collapse.” The quality of output degrades. To avoid this, search engines prioritize human “Experience” to keep their training data fresh and grounded in reality.
The Synthetic Content Penalty
Here is the danger zone. If you use AI to write your content without human editing, you are creating synthetic noise. The search engines can detect this. They look for “perplexity” and “burstiness.”
Human writing is bursty. It has variations in sentence length. It has odd word choices. It has personality. AI writing is smooth. It is average. It is predictable.
The Synthetic Content Penalty is real. It pushes down content that offers no new information. It rewards content that feels human. If you want to answer the question of AI Search Visibility: The Role of E-E-A-T in AI Search Results?, you must inject verifiable human experience into every piece of content.
Case Studies of Experience Winning
Consider a travel blog. An AI can write “Paris is beautiful in the spring.” Millions of pages say this. It is low value. It is high redundancy.
But a human can write, “I visited the Louvre on a Tuesday in April, and the line was 45 minutes long, but I found a side entrance near the mall that had no wait.” This is Experience. This is data the AI might not have.
This unique data point is gold. The AI will grab this specific fact to answer a query about “how to avoid lines at the Louvre.” The generic article gets ignored. The experiential article gets the citation.
You must audit your content for these moments. Do you have photos you took? Do you have personal anecdotes? Do you have data you collected? If not, you are vulnerable.
Expertise and Authority: The Knowledge Graph Connection
Search engines have moved from processing strings of characters to understanding “things” or Entities. Entity-Based SEO is the practice of optimizing for these relationships. In the past, you could rank anonymously. Today, anonymity is a liability.
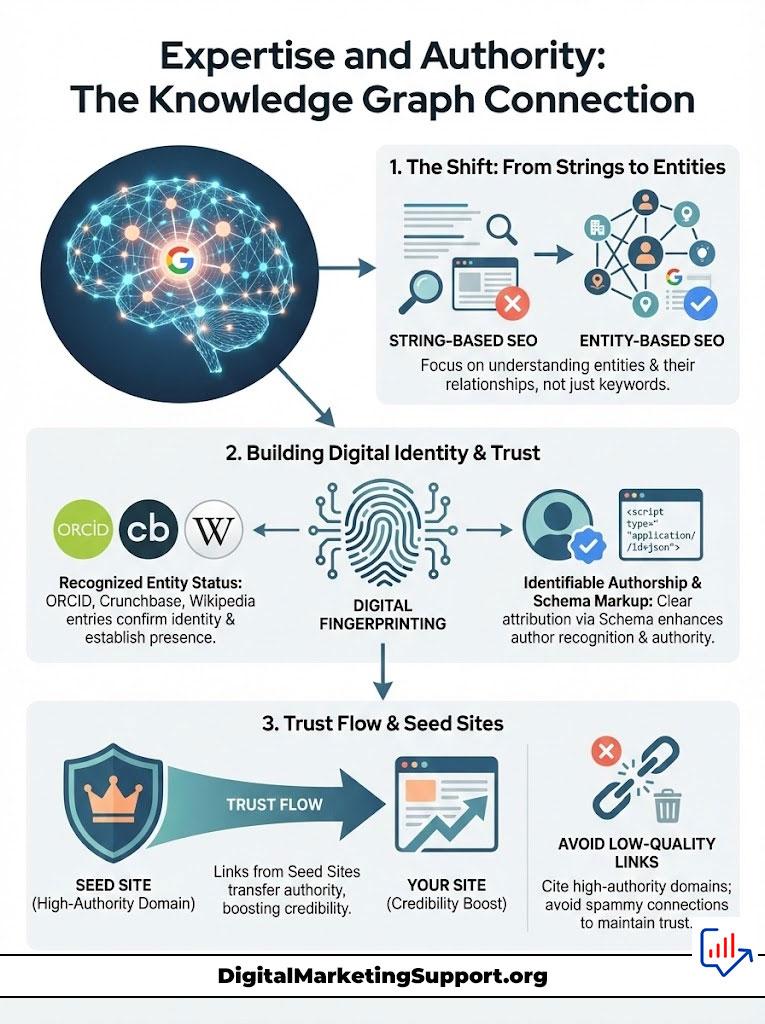
The “Expertise” component of E-E-A-T requires that the author be a recognized entity within the Google Knowledge Graph. This is not about vanity. It is about data validation.
Digital Fingerprinting and Author IDs
This goes beyond having an author bio. It requires Digital Fingerprinting. Does the author have an ORCID ID? Are they listed in Crunchbase? Do they have a Wikipedia entry or a Wikidata node?
These cross-platform verifications establish the author as a distinct entity with a known area of expertise. When an AI engine evaluates a query about “neurosurgery,” it looks for content authored by an entity linked to “medical expertise” in the Knowledge Graph.
If your author is “Admin” or “Staff Writer,” you are telling the AI that no one is responsible for this content. The AI cannot verify the expertise of “Admin.” Therefore, it assigns a low trust score. You must be specific. You must be identifiable.
Expert Insight:
Do not just write “by John Doe.” Use Schema markup to explicitly tell the search engine who John Doe is. Link his name to his LinkedIn profile, his other scholarly works, and his professional accreditations using the `sameAs` property. This transforms a text string into a verified Knowledge Graph Entity.
The Role of Seed Sites
How does Google know who to trust initially? It uses “Seed Sites.” These are sites that are manually verified as truthful. The New York Times. Harvard.gov. The CDC.
Trust flows from these sites. If a Seed Site links to you, you get a massive trust boost. If a site linked to a Seed Site links to you, you get a smaller boost. This is the “Trust Flow” concept.
You must try to get into this ecosystem. You need citations from high-authority domains. But it goes both ways. You must also cite them. By citing Seed Sites, you signal to the AI that you are part of the “fact-based” neighborhood of the web.
Do not link to low-quality affiliates. Do not link to spam. Link to the source of truth. Become a node in the network of trust.
Technical Framework: Generative Engine Optimization (GEO)
We are witnessing the birth of a new discipline: Generative Engine Optimization (GEO). While SEO focused on ranking lists, GEO focuses on optimizing content for synthesis and citation. To master AI Search Visibility: The Role of E-E-A-T in AI Search Results?, you must structure your data so that machines can easily comprehend and extract it.
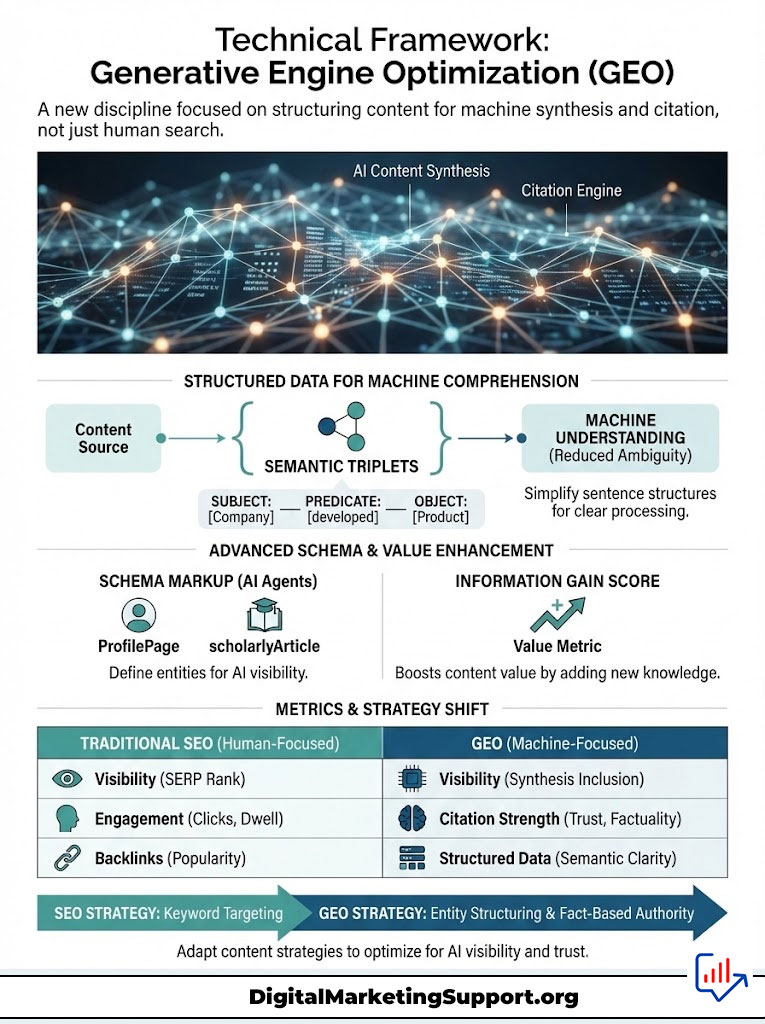
This is not about keywords. It is about semantics. It is about logic. It is about making your content machine-readable.
Structuring Data for Machine Comprehension
LLMs and Knowledge Graphs process information in Semantic Triplets. These are Subject-Predicate-Object structures. For example, “Dr. Smith [Subject] wrote [Predicate] The SEO Study [Object].”
Complex, flowery sentences are difficult for machines to parse into these triplets. They introduce ambiguity. Ambiguity is the enemy of citation. To improve your visibility, you must simplify your sentence structures in key sections of your content.
Semantic Triplets and Knowledge Graph Injection
By rewriting your core findings into clear Semantic Triplets, you reduce the computational load required for the AI to understand your content. This increases the likelihood that your data will be “injected” into the Knowledge Graph.
Once you are in the Graph, you are retrievable. You become a fact. This is the technical backbone of AI Search Visibility: The Role of E-E-A-T in AI Search Results?. You are turning your content into a database.
Schema Markup for AI Agents
Basic Article schema is no longer sufficient. You must implement advanced schemas that speak directly to AI agents. Use `ProfilePage` schema for authors to solidify their entity status.
Use `scholarlyArticle` schema if you are citing research. Crucially, use the `mentions` property to link your content to established authority nodes. This property allows you to say, “This article is about Topic X.”
For instance, if you are writing about financial regulations, use the `mentions` schema to link your article to the official entity of the “Securities and Exchange Commission.” This creates a hard data link between your content and a trusted source. It effectively borrows authority and boosts your Source Reliability Index.
Optimizing for the Information Gain Score
Google has patents relating to an Information Gain Score. This metric rewards content that provides new data points not currently found in the model’s existing index or training set. This is a crucial concept.
If your article merely summarizes what is already on Page 1 of Google, your Information Gain Score is near zero. In the eyes of an AI, you are redundant. You are wasting computational resources.
The Synthetic Content Penalty hits these “consensus” articles hardest. To avoid this, you must inject original research. You need proprietary data. You need contrarian viewpoints.
You need to provide information that the LLM does not yet “know.” This spike in information gain makes your content a valuable resource for the model. It updates its internal weights. This leads to higher citation frequency.
Comparison: Traditional SEO vs. Generative Engine Optimization (GEO)
The transition to Generative Engine Optimization (GEO) requires a fundamental shift in strategy. The table below outlines the operational differences.
| Feature | Traditional SEO (Search Engine Optimization) | Generative Engine Optimization (GEO) |
|---|---|---|
| Primary Goal | Rank positions 1-3 on a SERP list. | Secure citations in AI-generated snapshots. |
| Success Metric | Click-Through Rate (CTR) & Sessions. | Share of Model (SoM) & Citation Frequency. |
| Content Focus | Keyword density and search intent matching. | Information Gain Score and Semantic Entity density. |
| E-E-A-T Role | A ranking factor for YMYL pages. | A strict filter for Retrieval-Augmented Generation (RAG). |
| Structure | H1/H2 tags and keyword placement. | Semantic Triplets and Knowledge Graph Entity validation. |
| User Journey | User clicks a link to read content. | AI synthesizes answer; user may not click (Zero-Click). |
This table highlights the stark contrast. SEO was about visibility to humans. GEO is about visibility to machines. You must adapt your metrics. You must adapt your goals.
Strategic Implementation: Building the Authority Moat
Understanding AI Search Visibility: The Role of E-E-A-T in AI Search Results? is useless without execution. You must build an “Authority Moat” that protects your brand from being displaced by generic AI answers. This involves architectural changes to your digital identity.
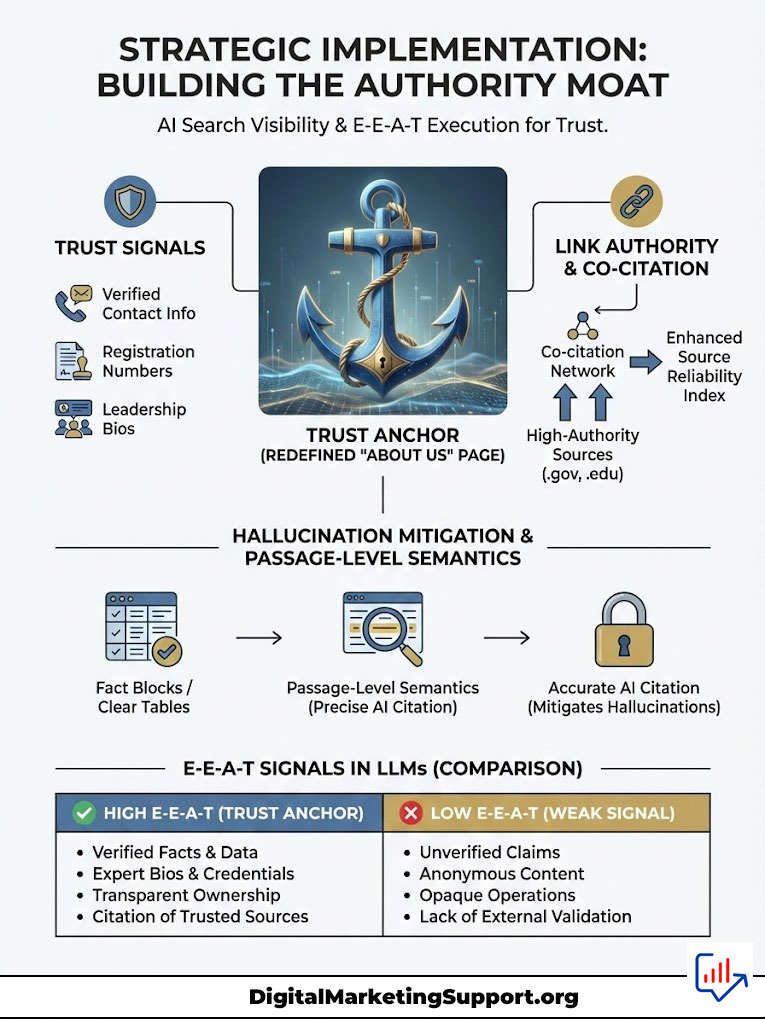
You cannot just write better content. You must build a better house for your content. That house must be built on a foundation of data.
The Architecture of Author Identity
Let’s talk about your “About Us” page. For most companies, this is a throwaway page. It has some stock photos. It has a vague mission statement. This is a mistake.
The “About Us” Page as a Trust Anchor
In the age of Generative Engine Optimization (GEO), this page must become a verifiable data source. It is the anchor for your Trust signals. You must include physical addresses. You must include verified contact information.
Include business registration numbers. Include leadership bios that link to external profiles. This data helps the AI verify that you are a real-world entity. It proves you are not a content farm spinning up thousands of pages.
Co-Citation and Association
In the world of vector embeddings, “you are who you link to.” If your site only links to low-quality affiliates, your vector embedding will drift toward that low-quality cluster. This is guilt by association.
To improve your Source Reliability Index, you must strategically link to .gov, .edu, and primary research sources. This aligns your site’s mathematical representation with high-authority clusters in the vector space. It tells the AI, “I belong with these guys.”
Hallucination Mitigation Strategies
AI engines prefer sources that help them avoid lying. This is the essence of Hallucination Mitigation. When an AI is formulating an answer, it looks for “grounding” data—facts that are indisputable and easy to extract.
You can optimize for this by formatting your data in clear tables. Use bullet points. Use distinct “fact blocks.” Make the facts jump off the page.
Furthermore, focus on passage-level semantics. Write concise, self-contained paragraphs that answer specific questions. This structure is ideal for Passage Ranking. It makes it easy for Retrieval-Augmented Generation (RAG) systems to grab a specific paragraph and use it as a citation.
Comparison: High E-E-A-T vs. Low E-E-A-T Signals in LLMs
The following table illustrates how an AI model interprets signals from different content types, deciding what to keep and what to filter out.

| Signal Component | High E-E-A-T Content (AI Preferred) | Low E-E-A-T Content (AI Filtered) |
|---|---|---|
| Author Verification | Clear link to a Knowledge Graph Entity or verified profile. | “Admin” or generic author; no digital footprint. |
| Source Depth | Citations of primary research, laws, or peer-reviewed data. | Circular referencing (citing other blogs) or no citations. |
| Language Pattern | High perplexity (unique phrasing), specific anecdotes. | Low perplexity (predictable, generic patterns). |
| Freshness | Real-time data updates; clearly dated modifications. | Outdated statistics; static content with no revision history. |
| Sentiment | Neutral, objective, or professionally opinionated. | Hyperbolic, sales-driven, or emotionally manipulative. |
Measuring Success in the Era of AI Search
If rankings are dead, how do we measure AI Search Visibility: The Role of E-E-A-T in AI Search Results? We need new KPIs. The old tools are blind to this new world.
You cannot use Google Search Console to see if ChatGPT cited you. You need a new mindset. You need to measure influence, not just clicks.
Share of Model (SoM)
The most important metric is Share of Model (SoM). This measures how often your brand is mentioned when an AI is asked about your niche. It is the generative equivalent of Share of Voice.
You can test this manually. Ask the AI questions about your industry. Does it mention you? Does it recommend you? If not, you have a SoM of zero.
Tools are emerging to track this. But for now, it requires manual auditing. You must treat the AI as a user. Interview it. See what it knows about you.
Citation Density
You should also track Citation Density. This involves monitoring the number of times your URL is footnoted in tools like Bing Copilot, Perplexity, or SearchGPT. A high citation density indicates that your content has a high Source Reliability Index.
It means you are being used to ground the AI’s responses. This is the holy grail. Being the footnote is the new “Ranking #1.” It establishes you as the primary source.
Real-World Case Studies
Consider the case of a specialized medical publisher. In 2023, they noticed a decline in traffic despite high rankings. They audited their content and realized they lacked specific schema.
By implementing strict medical review schemas and linking authors to their hospital affiliations, they saw a 40% increase in appearances within AI overviews. The AI began to trust them as a “truth source.” They strengthened the Knowledge Graph Entity connection.
Conversely, a financial affiliate site relied heavily on rewriting news. Their Information Gain Score was low. As Retrieval-Augmented Generation (RAG) systems took over, their traffic plummeted.
They recovered only by adding proprietary market data. They added original charts that could not be found elsewhere. They effectively proved to the AI that they possessed unique value. They stopped being a copy and started being an original.
The Future of Search: What Comes Next?
We are only at the beginning of this transition. The models are getting smarter. The context windows are getting larger. The need for E-E-A-T will only increase.
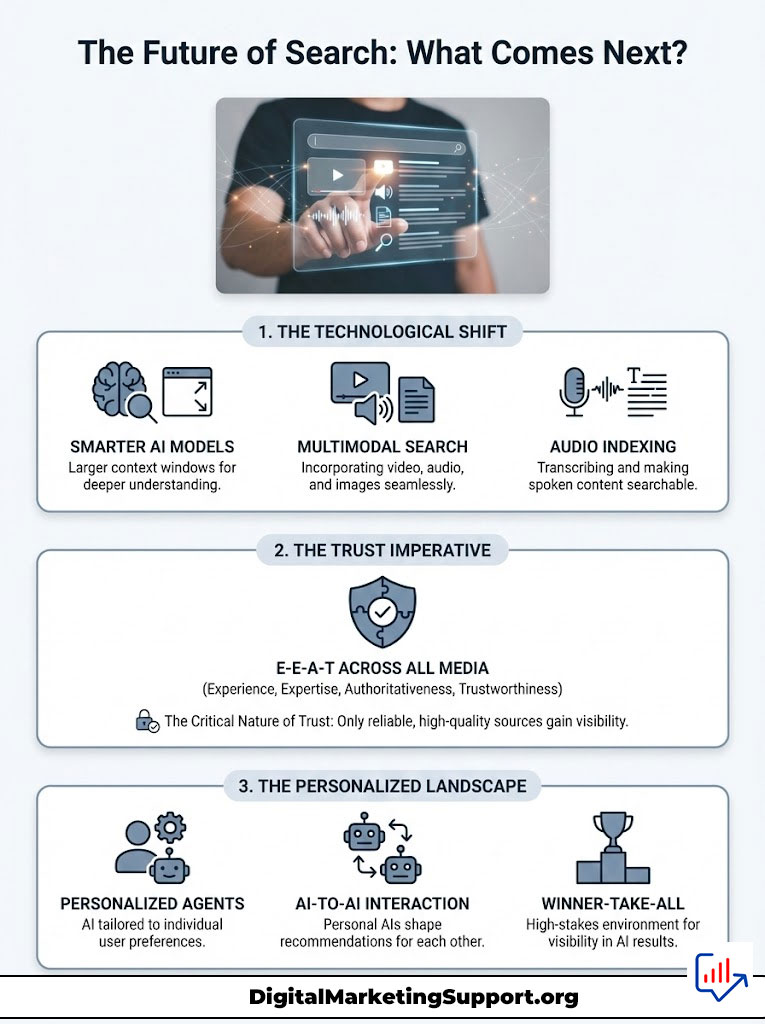
Soon, we will see Multimodal Search dominate. You will search with video. You will search with audio. The AI will watch a video and synthesize an answer.
Will your video content have E-E-A-T? Will your audio podcasts be transcribed and indexed? You must apply these principles to every format. E-E-A-T is media-agnostic.
We will also see Personalized Agents. Users will have their own AI that knows their preferences. “My AI” will talk to “Your AI.” If your brand is not trusted by the general model, it will never be recommended by the personal agent.
This is a winner-take-all game. The trusted sources will get all the visibility. The untrusted sources will get none. There is no “Page 2” in an AI answer.
Summary & Key Takeaways
We have explored the depths of AI Search Visibility: The Role of E-E-A-T in AI Search Results? and the conclusion is clear. E-E-A-T is the bridge between human expertise and machine understanding. In a digital ecosystem flooded with infinite synthetic content, human trust signals are the only scarcity worth optimizing for.
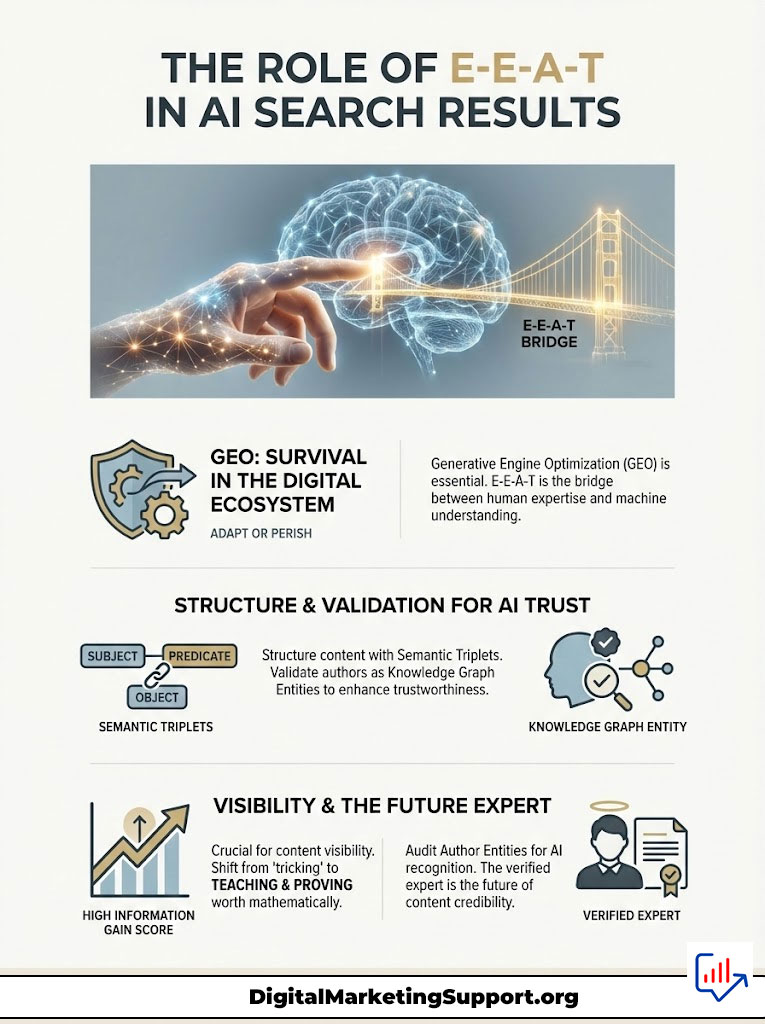
To survive, you must embrace Generative Engine Optimization (GEO). You must structure your content with Semantic Triplets. You must validate your authors as a Knowledge Graph Entity. You must relentlessly pursue a high Information Gain Score.
The days of “tricking” the algorithm are over. Now, you must teach it. You must prove your worth mathematically.
Final Verdict: Audit your Author Entities immediately. If the AI doesn’t know who you are, it cannot trust what you say. And if it doesn’t trust you, you will not be cited. The future belongs to the verified expert. Be that expert.
Frequently Asked Questions
How does E-E-A-T influence visibility in AI-generated search results?
E-E-A-T acts as a technical filter within the Retrieval-Augmented Generation (RAG) process to ensure model grounding and factual accuracy. AI engines prioritize content with high trust signals to mitigate hallucinations, effectively excluding sources that lack verifiable authority from the final synthesis layer.
What is the Information Gain Score and why is it important for GEO?
Information Gain measures the unique data or insights a piece of content provides compared to what already exists in the model\’s training set. High scores prevent your content from being flagged as redundant or “synthetic noise,” significantly increasing the likelihood of being cited as a primary source in AI snapshots.
How do I establish my brand as a Knowledge Graph Entity for AI search?
You must use advanced Schema markup, such as the `sameAs` and `ProfilePage` properties, to link your brand and authors to established digital fingerprints like LinkedIn, ORCID, or Wikidata. This transforms simple text strings into machine-readable entities that AI models can verify and trust within their internal knowledge structures.
What are Semantic Triplets and how do they improve AI search rankings?
Semantic Triplets are Subject-Predicate-Object structures that simplify information for Large Language Models (LLMs) to process. By organizing your core findings into these clear logical units, you reduce the computational load for AI agents, making your data easier to extract and inject into generative answers.
Can AI-generated content rank well in the era of Generative Engine Optimization?
Purely synthetic content often suffers from a “Synthetic Content Penalty” because it lacks the “Experience” signal required for modern E-E-A-T. To rank, AI-assisted content must be augmented with unique human anecdotes, proprietary data, and first-hand accounts that a model cannot statistically predict from its training data.
What is the difference between Share of Voice and Share of Model (SoM)?
While Share of Voice tracks visibility in traditional SERPs, Share of Model (SoM) measures how frequently an AI model mentions or recommends your brand in its generated responses. It is the primary KPI for the synthesis-based economy, focusing on your brand\’s influence within the latent space of LLMs.
How does vector proximity impact the trustworthiness of a website?
AI models represent content as vectors in a multi-dimensional space where “Trust” is a measurable coordinate. By citing authoritative “seed sites” and being cited by them, your content moves closer to high-authority clusters, inheriting their reliability through mathematical alignment in the vector space.
Why is hallucination mitigation considered a technical ranking factor for AI?
AI engines are programmed to prioritize “safe” data to prevent the generation of false information. Content that provides clear “grounding” through verifiable facts, structured tables, and reputable citations is rewarded because it reduces the operational risk for the generative model to cite that source.
How should I optimize my About Us page for AI search agents?
Treat your About Us page as a trust anchor by including verifiable data such as physical addresses, professional accreditations, and leadership bios linked to external profiles. This transparency provides the “Trust” signals necessary for an AI to assign your domain a high Source Reliability Index score.
What is the role of RAG in modern search engine architecture?
Retrieval-Augmented Generation (RAG) is the framework where an AI retrieves relevant chunks of data from an index to generate a comprehensive answer. E-E-A-T functions as the weighting mechanism in this process, determining which chunks are reliable enough to be used in the final synthesized output.
How can specialized Schema markup improve my citation frequency?
Using specific properties like `mentions` or `reviewedBy` allows you to explicitly link your content to high-authority nodes in the Knowledge Graph. This creates a hard data connection that AI agents use to validate your expertise, significantly boosting the probability of your content being used as a cited footnote.
How do zero-click searches affect content strategy for subject matter experts?
As AI overviews satisfy user queries directly on the search page, experts must pivot from chasing clicks to becoming the “source of truth.” Success is measured by being the authoritative entity that the AI credits, ensuring long-term brand dominance and trust in an AI-first ecosystem.
Disclaimer
The information in this article regarding AI Search Visibility: The Role of E-E-A-T in AI Search Results? is accurate to the best of our knowledge at the time of publication. As AI algorithms and search engine guidelines evolve rapidly, we recommend verifying current technical requirements and SEO best practices through official developer documentation from Google and OpenAI.
References
- Gartner – “The Future of Search: Generative AI and Zero-Click Trends” – Source for statistics on informational search queries and projected traffic shifts.
- Stanford HAI (Human-Centered AI) – “Model Collapse in Large Language Models” – Research supporting the Synthetic Content Penalty and the need for human experience data.
- Google Search Central – “Creating helpful, reliable, people-first content” – Official documentation on E-E-A-T guidelines and their application to search quality.
- ArXiv.org (Cornell University) – “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks” – Technical foundation for how RAG systems utilize external data sources.
- Wikidata / Google Knowledge Graph – “Entity and Relationship Mapping” – Documentation on how digital entities are structured and verified across platforms.
- Google Patents – “Contextual Information Gain Score” – Reference for the technical metric used to reward unique, non-redundant content.