








To achieve high Data Table SEO, you must strictly utilize semantic HTML5 tags including <thead>, <th>, and specific scope attributes. AI agents like SearchGPT and Perplexity rely on these structural markers to map data relationships and token context. By integrating Schema.org Dataset markup and ensuring machine-readable headers, you transform static grids into structured context for Retrieval-Augmented Generation (RAG), effectively guaranteeing your data can be extracted and cited in AI-generated responses.
Table of Contents
The Shift from Visual Scanning to Machine Extraction
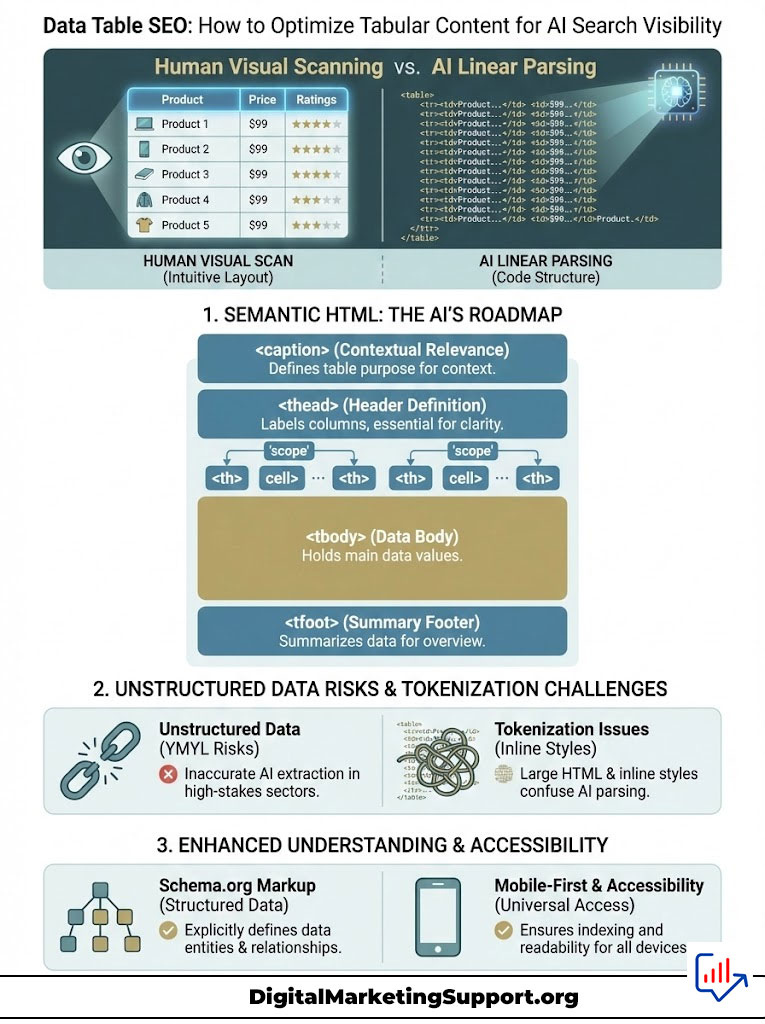
The era of designing exclusively for the human eye is over. While your user interface must remain intuitive for human visitors, the underlying architecture of your data now serves a second, equally critical audience: Large Language Models (LLMs). When a user asks a complex question to Google AI Overviews or Claude, the engine does not look at your table like a human does. It reads the code. It parses tokens. It looks for semantic relationships that bind a specific cell to a specific header.
If your pricing tiers, product specifications, or financial reports are built using messy <div> structures or lack clear row-column associations, that data is effectively invisible. It becomes “unstructured noise” that RAG systems will ignore to avoid the risk of hallucination.
Data Table SEO is no longer a niche technical task. It is a fundamental requirement for brand survival in an AI-first search landscape. If you want your proprietary data to fuel the answers given to millions of users, you must speak the language of the machine. This guide outlines the precise engineering required to turn your tables into high-value knowledge assets.
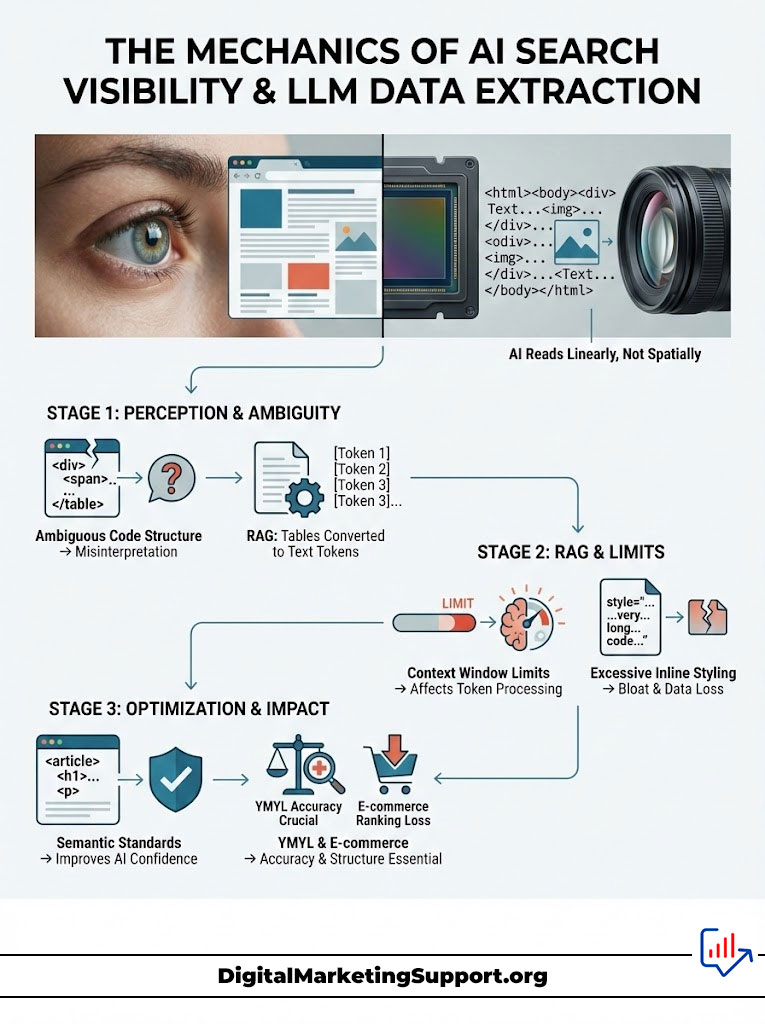
The Mechanics of AI Search Visibility and LLM Data Extraction
To dominate AI search visibility, you must understand how an AI reads. Unlike a human who scans a table spatially, associating the number “$50” with the column “Premium Plan” based on visual alignment, an AI bot like OAI-SearchBot parses the HTML raw. It reads linearly.

How Retrieval-Augmented Generation (RAG) Processes Tabular Data
LLM Data Extraction relies on predictability. When a model like GPT-4o or Gemini 1.5 Pro crawls a page, it converts your table into a sequence of text tokens. If the code structure is ambiguous, the model cannot confidently assert that a specific value belongs to a specific category.
Consider a scenario involving a financial services website. The site lists interest rates in a visual grid but uses simple <td> tags for everything, relying on bold font to indicate headers. To a human, the hierarchy is clear. To an AI, this is a flat list of numbers and words without direction.
When a user asks, “What is the interest rate for a 5-year CD?” the AI analyzes the tokens. Without semantic tags, the probability of the AI hallucinating (perhaps pulling the 3-year rate instead of the 5-year rate) increases drastically. To prevent this error, the RAG system will often discard the data entirely in favor of a source with better structure. This is where Data Table SEO determines the winner.
The Hidden Cost of Unstructured Data Hallucinations in YMYL Niches
In “Your Money Your Life” (YMYL) sectors, accuracy is the primary ranking factor for both traditional SEO and AI citations. We have observed instances where e-commerce brands lost position in Google AI Overviews because their comparison tables lacked scope attributes. The AI could not definitively link “Battery Life” to the correct laptop model in a merged-cell layout.
By implementing strict semantic standards, you reduce the computational load on the AI. You provide it with a “confidence path.” When the AI is confident in the data relationship, it is more likely to extract that data and cite your URL as the authoritative source.
Tokenization Strategy for Large Language Models
A major technical constraint for LLM Data Extraction is the “context window.” Every AI model, from OAI-SearchBot to Perplexity, has a limit on how much text it can process at once. This is measured in tokens.
HTML tables can be token-heavy. A table with thousands of rows and excessive inline styling (like style=”border: 1px solid #ccc;” repeated on every cell) bloats the code. If your table code is 50kb of text, it might consume a significant portion of the AI’s allowed input. When the input limit is reached, the AI simply cuts off the rest of the data. This means the bottom half of your table literally does not exist to the model.
Technical Architecture for Structuring Data Tables for AI Scraping
Building for AI search visibility requires a return to strict HTML5 standards. You must abandon the habit of using tables for layout and focus entirely on tables for data representation.
Implementing Semantic HTML5 Standards for Machine Readability
The foundation of machine-readable data lies in three specific HTML tags: <thead>, <tbody>, and <tfoot>.
Utilizing Thead and Tbody Tags for Data Hierarchy
An AI bot needs to know where the labels end and the data begins. The <thead> tag encapsulates your column headers. This tells the LLM Data Extraction process that every piece of text inside this block is a “Key” in a Key-Value pair. Conversely, <tbody> contains the “Values.”
If you omit these tags and let the browser infer them, you force the AI to guess. In the world of tokenization, guessing costs references. You must explicitly define these boundaries in your code to ensure the machine understands the data hierarchy instantly.
Mapping Relationships with Scope Attributes for OAI-SearchBot
The most undervalued attribute in Data Table SEO is scope. This attribute is the GPS coordinate system for your data.
- scope=”col”: Applied to a <th> tag, it tells the bot that this header applies to every cell in the column below it.
- scope=”row”: Applied to the first cell of a row (often a <th>), it tells the bot that this header applies to the cells to the right.
Without scope, an AI model processing a complex matrix has to rely on heuristic proximity. By adding scope=”col”, you create a hard-coded link between the header “Q3 Revenue” and the cell “$4.5M” ten rows down. This hard-coded link is what facilitates accurate Retrieval-Augmented Generation (RAG).
Leveraging Caption Tags as Metadata for Contextual Relevance
The <caption> tag is often ignored by developers, yet it is vital for AI search visibility. Think of the caption as the H1 for your table. When an LLM scans a long page of content, it looks for signposts to determine relevance.
A clear, descriptive caption like “Comparative Technical Specifications of 2025 Enterprise Servers” allows the AI to instantly index the table’s intent. This metadata prevents the AI from having to “read” the entire table to guess what it is about, saving valuable processing tokens.
Comparative Analysis: Visual Tables vs. Semantic AI Structures
The following breakdown illustrates the difference between a standard web table and one optimized for AI search visibility.
| Feature | Standard “Visual” Table | AI-Optimized Semantic Table | Impact on AI Scraping |
| Header Tags | Often uses <b> or bold text for headers | Uses <th> tags exclusively | <th> signals a data label to the bot; generic bold text is just emphasis. |
| Relationship Mapping | Relies on visual alignment | Uses scope=”col” and scope=”row” | Explicitly links data cells to headers; essential for accurate RAG extraction. |
| Context | Surrounding paragraph text | Uses <caption> and summary attributes | Provides immediate topical relevance to the scraping bot before data parsing. |
| Mobile Handling | Hides columns via CSS (display:none) | Responsive scrolling or prioritized data | Hidden CSS data is often ignored by AI; semantic tables ensure indexing. |
| Cell Merging | Uses colspan for visual centering | Avoids merged cells where possible | Merged cells break the coordinate system for bots; flat structures are superior. |
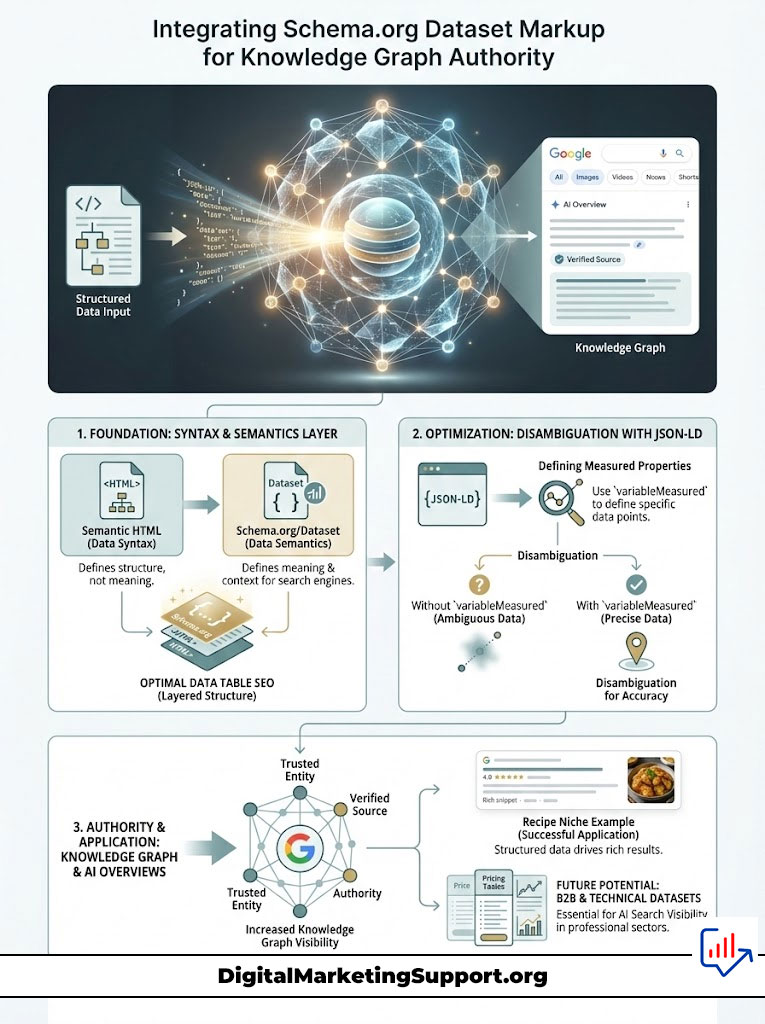
Integrating Schema.org Dataset Markup for Knowledge Graph Authority
While semantic HTML handles the “syntax” of your data, Schema.org/Dataset handles the “semantics” or meaning. Data Table SEO reaches its peak potential when you layer structured data on top of your HTML.
Deploying JSON-LD to Define Variable Measured Properties
Search engines like Google have moved toward a Knowledge Graph architecture. They want to understand entities, not just keywords. By wrapping your table data in JSON-LD using the Dataset schema, you are essentially handing the AI a cheat sheet.
You should define the variableMeasured property. This property allows you to list exactly what data points are contained in the table (e.g., “Price,” “Weight,” “SKU”). This disambiguates the content. If your table contains the number “2024,” the schema clarifies whether that is a year, a price, or a model number.
Bridging the Gap Between HTML Tables and Google AI Overviews
When you use Schema.org/Dataset, you increase the probability of your data being ingested into the Google Knowledge Graph. Google AI Overviews draw heavily from the Knowledge Graph because it is a verified source of truth.
An instance of this success can be seen in the recipe niche. Recipe cards with structured data (ingredients, cook time) dominate search results because the data is machine-readable. Applying this same logic to B2B pricing tables or technical data sets is the next frontier of AI Search Visibility.
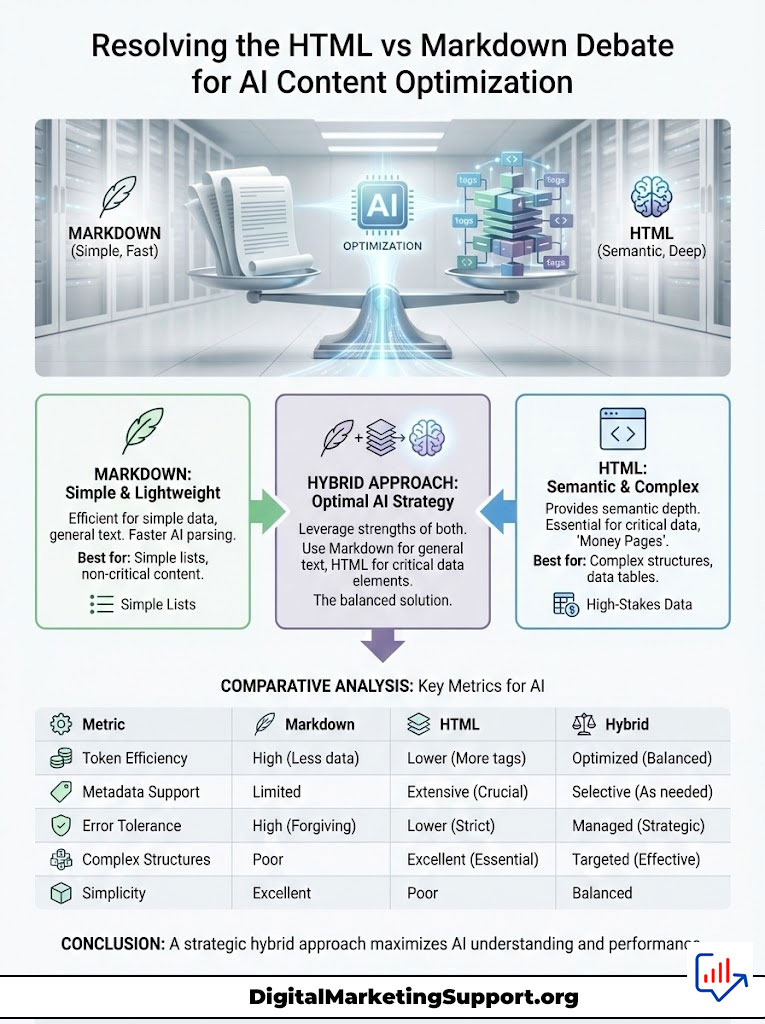
Resolving the HTML vs Markdown Debate for AI Content Optimization
There is an ongoing debate in the developer community regarding the best format for documentation: HTML or Markdown. For AI Search Visibility, the answer depends on the complexity of the data.
Analyzing Token Efficiency Against Semantic Precision
Markdown is lightweight. It uses very few tokens. For simple two-column lists, Markdown is highly efficient for LLM Data Extraction. However, Markdown lacks the semantic depth of HTML. It cannot handle scope, caption, or complex headers effectively.
If your data is simple (e.g., a list of feature availability), Markdown is acceptable and potentially faster for the AI to parse. However, for “Money Pages” (pricing comparisons, financial reports, or technical specs), HTML is mandatory. The risk of the AI misinterpreting the grid structure in Markdown is too high for high-stakes data.
When to Use Markdown for Lightweight Documentation Scrapers
Consider the documentation for a major software API. The sections written in Markdown are easily ingested by coding assistants like GitHub Copilot. However, for the detailed “Rate Limit” tables which define complex tiers and penalties, the documentation switches to semantic HTML. This hybrid approach ensures token efficiency for general text while maintaining strict structural integrity for the most critical numerical data.
Comparative Analysis: HTML vs. Markdown for AI
The table below outlines which format serves specific Data Table SEO goals.
| Attribute | HTML Tables | Markdown Tables | AI Preference |
| Complexity Handling | High (Merged cells, headers, footers) | Low (Simple rows/columns only) | HTML is better for complex financial or scientific data. |
| Token Efficiency | Lower (More tags/characters) | High (Clean, minimal syntax) | Markdown is better for simple lists to save context tokens. |
| Metadata Support | Excellent (Classes, IDs, ARIA roles) | Non-existent | HTML wins for SEO and entity tagging. |
| Error Tolerance | High (Browsers fix broken tags) | Low (Formatting breaks easily) | HTML is more robust for crawling consistency. |
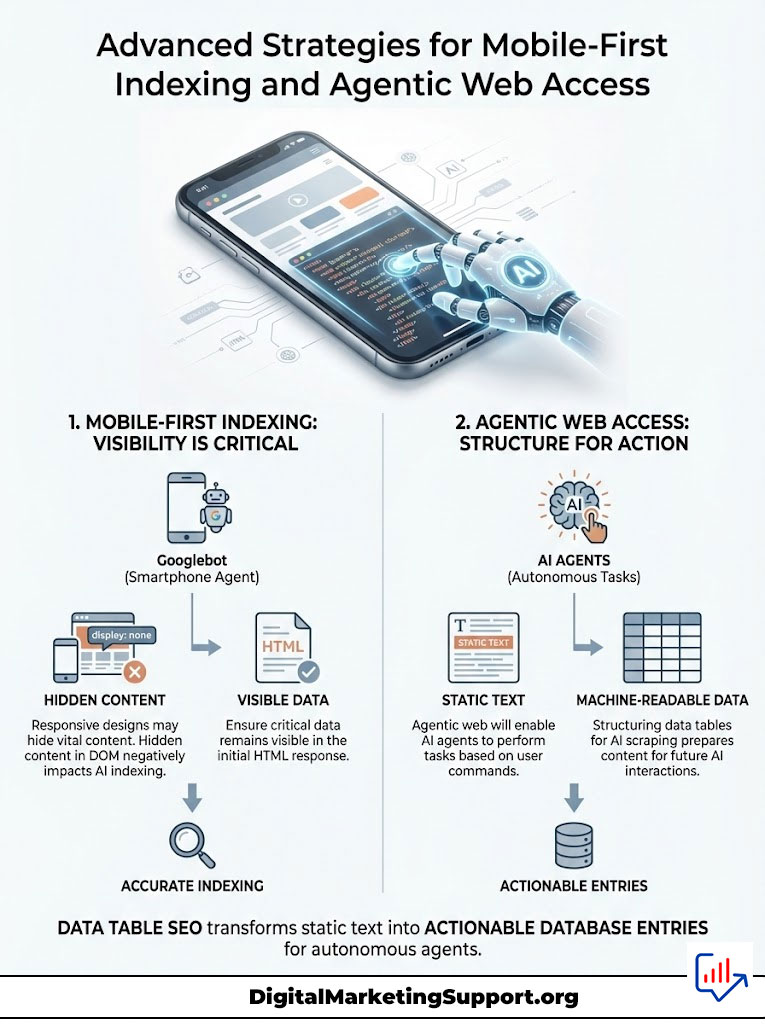
Advanced Strategies for Mobile-First Indexing and Agentic Web Access
It is critical to remember that Googlebot primarily uses a smartphone user-agent. Many responsive designs handle tables by hiding less important columns on mobile screens using display: none.
Overcoming CSS Display None Issues in Mobile-First Scraping
If the content is hidden in the DOM (Document Object Model) specifically for the mobile view, the AI bot scraping as a mobile user may not index it. Always ensure that your vital data remains in the source code, even if you use CSS to create a scrollable container for the user. AI search visibility depends on the data being present in the initial HTML response.
Future-Proofing Table Data for Autonomous AI Agents and Voice Search
We are moving toward an agentic web. Users will soon tell an AI agent, “Find the cheapest flight to New York,” and the agent will execute the task. These agents will rely entirely on machine-readable data.
By strictly structuring data tables for AI scraping today, you are preparing your content for this agentic future. Your tables will not just be read; they will be used to perform actions. This is the ultimate goal of Data Table SEO: transforming your content from static text into actionable database entries for the global AI infrastructure.
Auditing Protocol to Ensure High E-E-A-T and Data Accuracy
To maintain Authoritativeness and Trustworthiness, your data must be verifiable. You cannot fix what you cannot measure.
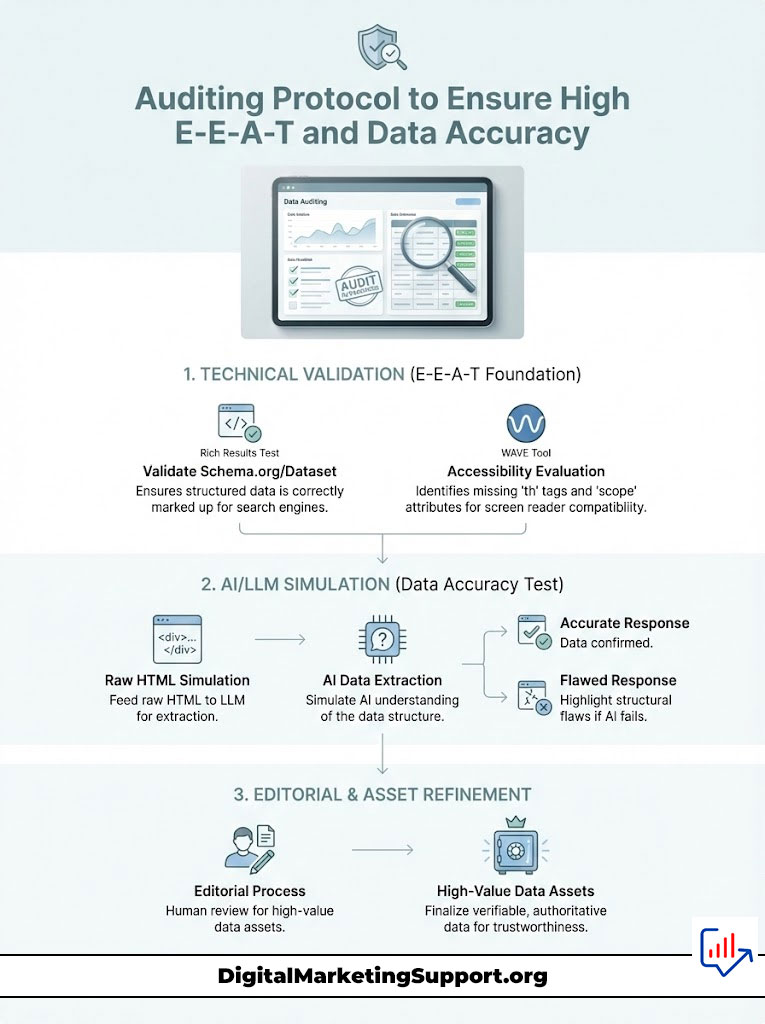
Using Rich Results Test and WAVE Tools for Structural Validation
Use the Rich Results Test to verify that your Schema.org/Dataset markup is valid and error-free. Furthermore, utilize the WAVE Web Accessibility Evaluation Tool. This accessibility tool highlights missing th tags and scope attributes. If a screen reader cannot read it, OAI-SearchBot likely cannot understand it.
Simulating LLM Extraction to Verify Data Integrity
Paste your table’s raw HTML into a model like ChatGPT and ask it specific questions about the data. If the AI fails to answer correctly or hallucinates a value, your structure is flawed. This “LLM Simulation” is a critical step in the editorial process before publishing any high-value data asset.
Summary & Key Takeaways
- Semantic Foundation: Success in AI Search Visibility begins with HTML5 tags (<thead>, <th>, scope). These are not optional decorations; they are the syntax AI uses to understand data.
- Relationship Mapping: The scope attribute is the single most important tool for preventing AI hallucinations in complex tables. It hard-codes the link between headers and data cells.
- Schema Integration: Implementing Schema.org/Dataset with JSON-LD provides a machine-readable layer of context that bridges the gap between your raw code and the Knowledge Graph.
- Token Optimization: Large tables must be optimized for token efficiency by removing inline styles and breaking massive datasets into thematic chunks to fit within LLM context windows.
- Format Selection: Use Markdown for simple, token-light lists, but strictly adhere to semantic HTML for complex, high-stakes data to ensure accuracy.
- Mobile Indexing: Ensure your table data is fully present in the mobile source code, as AI bots often crawl as mobile user-agents.
Frequently Asked Questions
What is the most critical HTML tag for AI table scraping?
The <th> tag combined with the scope attribute is the most critical. It creates a definitive link between the label and the data. Without scope, the AI has to guess the relationship between a cell and its header, which leads to extraction errors.
Does converting tables to images hurt SEO?
Yes, utilizing images for tables destroys AI search visibility. While some models possess Optical Character Recognition (OCR), it is resource-intensive and often inaccurate. Text-based HTML is the only way to ensure your data is crawled, indexed, and cited by search engines.
How does Schema.org Dataset markup help with AI?
Schema.org/Dataset provides a machine-readable layer that explains the context of your table. It helps Google AI Overviews and other engines understand what variables are being measured (e.g., currency, weight, time) without having to parse the visual grid.
Can AI bots read tables hidden behind tabs?
It varies by bot. Advanced crawlers like Googlebot can render JavaScript to see tabbed content, but many RAG scrapers prefer raw, static HTML. For maximum visibility, critical data should be visible in the initial HTML source code rather than hidden behind user interactions.
Why is my table data not showing up in Google AI Overviews?
The most common reasons are poor semantic structure (using divs instead of tables), lack of authority, or excessive complexity (nested tables) that confuses the parser. Validating your code with the Rich Results Test is a good first step.
Is Markdown better than HTML for AI tokens?
Markdown is more token-efficient, meaning it takes up less “memory” in the AI’s context window. However, it lacks the semantic precision of HTML. For simple lists, Markdown is excellent; for complex data, HTML is superior for Data Table SEO.
What is the role of the caption tag?
The <caption> tag serves as the title or “Alt Text” for your table. It helps LLM Data Extraction algorithms quickly determine if the table is relevant to the user’s query before processing the rows and columns.
How do I test if my table is AI-friendly?
You can use accessibility tools like WAVE to check for semantic structure. Additionally, copy your table’s raw HTML and paste it into an LLM like ChatGPT. Ask the AI to extract specific data points; if it struggles, your structure needs improvement.
Does table size affect AI crawling?
Yes. Extremely large tables can exceed the “context window” of an LLM, causing the model to stop reading halfway through. It is best practice to split massive datasets into smaller, logically categorized tables with clear headers.
Do CSS styles affect AI scraping?
Visual CSS generally does not affect scraping, but structural CSS does. If you use display: none to hide columns on mobile devices, mobile-first bots may exclude that data from their index. Always ensure vital data is rendered in the DOM.
Why is the scope attribute necessary if I already use th tags?
While <th> identifies a header, it doesn’t specify direction. In complex tables where headers might be in the first column and the first row, scope=”col” and scope=”row” clarify exactly which cells belong to which header, eliminating ambiguity for the AI.
How do I cite sources in an AI-friendly table?
Use the <tfoot> tag to house citations, or include hyperlinks directly within the relevant cells. This builds Trustworthiness and helps AI models verify the data’s origin, increasing the likelihood of citation.
Disclaimer
The information provided in this article regarding AI search algorithms and bot behaviors is based on current technical standards and observations of Large Language Model (LLM) performance as of the time of writing. Search engine algorithms, including those of Google and OpenAI, are subject to frequent updates. Webmasters are encouraged to stay current with official documentation from W3C and major search platforms.
References
- W3C Recommendation: HTML5 Table Elements and Attributes.
- Schema.org Documentation: Dataset and Table vocabularies.
- Google Search Central: Structured Data General Guidelines.
- OpenAI Developer Documentation: Best Practices for Knowledge Injection.