








The digital marketing playbook of 2024 is already obsolete. In 2025, U.S. marketers face a perfect storm: persistent economic uncertainty demanding greater ROI, the final sunsetting of third-party cookies forcing a hard pivot to first-party data, and the relentless pace of AI innovation. Survival and growth now depend on leveraging this AI not just for basic automation, but for real-time, hyper-personalized customer engagement at an unprecedented scale.
Table of Contents
While Large Language Models (LLMs) offer the creative and analytical power, their practical application hinges on a critical, often-overlooked component: the engine that serves them. This is where AI inference engines become the linchpin of modern marketing, determining the speed, cost, and effectiveness of every AI-driven interaction. The right large language model serving platform is no longer a backend IT concern; it’s a frontline marketing imperative.
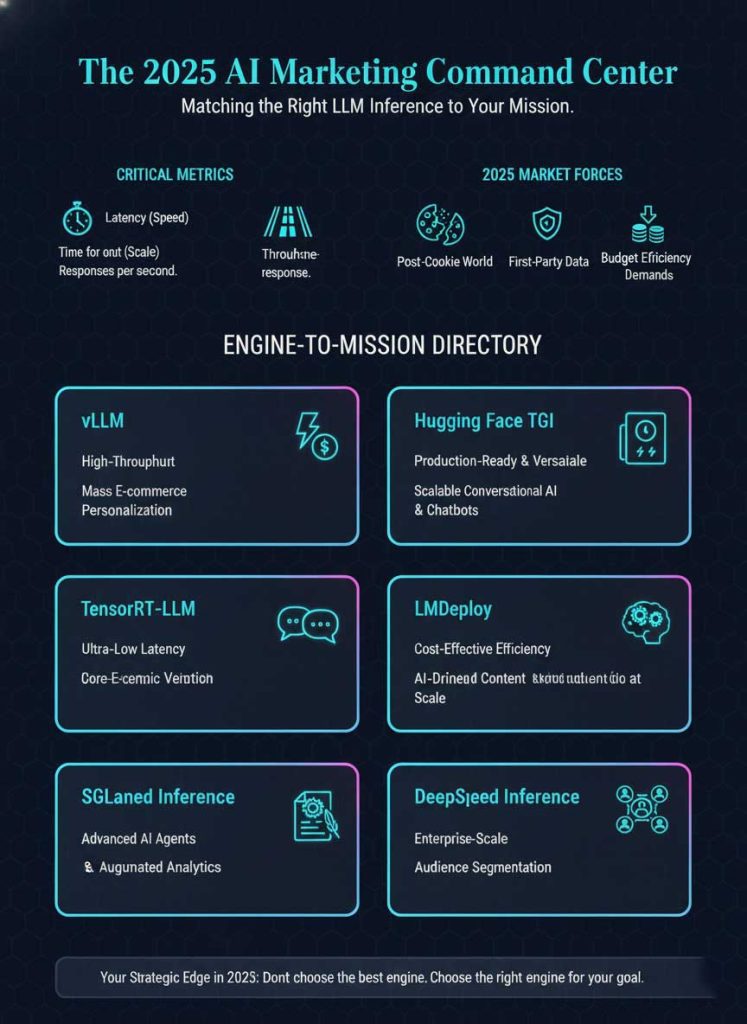
This deep dive moves beyond the hype to provide a definitive guide to the top 6 inference engines shaping digital marketing trends 2025. We will break down their technical strengths, analyze their best-fit marketing use cases, and provide a strategic framework for selecting the right engine to build a resilient, high-performing martech stack with robust USA AI infrastructure.
The Engine Behind the Magic: What Are AI Inference Engines and Why Do They Matter in 2025?
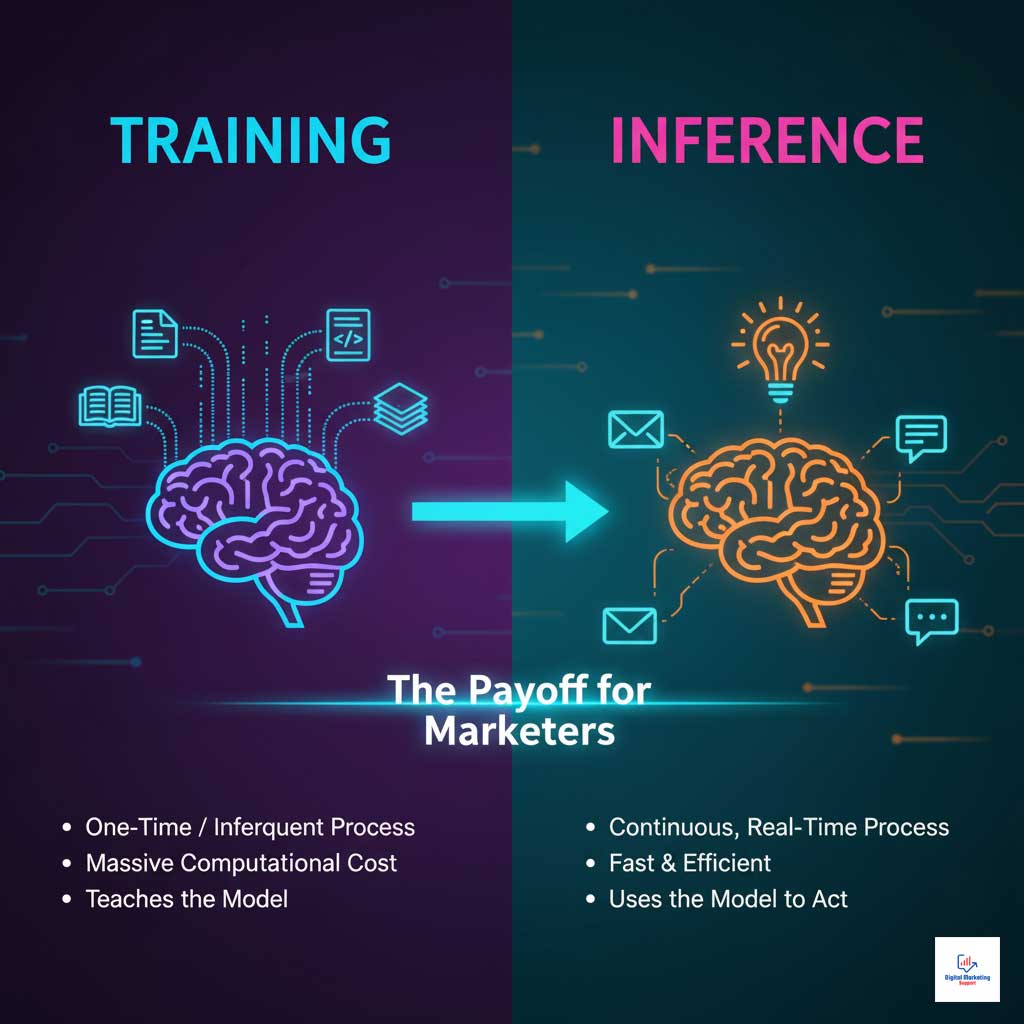
At its core, an AI inference engine is the operational software that runs a trained AI model to make predictions or generate new content. If an LLM is the brilliant “brain” that has learned from vast amounts of data, the inference engine is the “central nervous system” that allows that brain to think, respond, and act in real time.
This distinction is crucial for marketers. The process of training an LLM is a massive, resource-heavy effort, but it’s often a one-time or infrequent event. The process of inference happens continuously, every single time a customer sees a personalized ad, interacts with a chatbot, or receives a tailored email. This is where the magic of generative AI for marketers truly happens.
The performance of these real-time inference engines directly impacts campaign ROI in three critical ways:
- Latency: The delay between a request and a response. In AI for digital advertising, low latency means winning a real-time bid; high latency means losing the opportunity.
- Throughput: The number of requests the engine can handle simultaneously. High throughput makes omnichannel personalization AI for millions of users financially viable.
- Cost: The computational resources required for each inference. An efficient engine lowers the cost per interaction, maximizing marketing budgets.
Understanding these factors transforms the conversation about LLM deployment 2025 from a technical discussion into a strategic business decision.

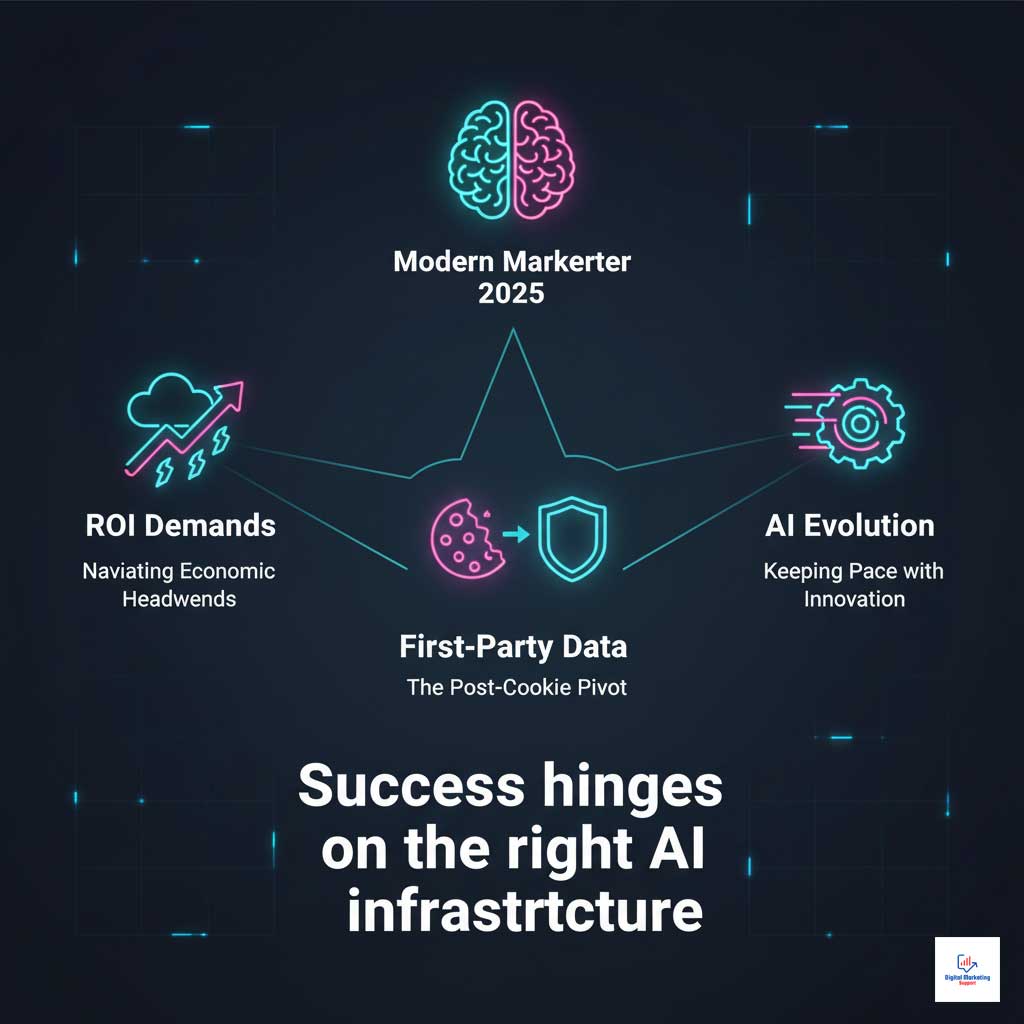
The Tectonic Shift: Economic and Market Forces Shaping AI Adoption in U.S. Marketing
The drive to adopt advanced AI marketing automation tools isn’t happening in a vacuum. It’s a direct response to powerful market forces that are fundamentally reshaping the digital landscape in the United States.
Navigating the Post-Cookie Reality with a First-Party Data Strategy
The final phase-out of third-party cookies has forced a hard pivot to a first-party data strategy. Brands are now sitting on mountains of proprietary customer data, but its value is locked until it can be activated. This is where AI inference engines become indispensable. They provide the power to process this data securely, uncovering deep insights and enabling hyper-personalized marketing at a scale previously unimaginable.

Economic Pressure and the Mandate for AI Performance Optimization
Amidst global economic shifts and tightening budgets, the C-suite is demanding more accountability and measurable ROI from marketing spend. This pressure makes AI performance optimization a non-negotiable priority. Marketers must choose AI inference engines that maximize hardware utilization and minimize operational costs, thereby lowering the Total Cost of Ownership (TCO) of their USA AI infrastructure. Efficient large language model serving is now synonymous with fiscal responsibility.
The Explosion of Generative AI Beyond Text
The initial wave of generative AI for marketers focused heavily on text-based content. Now, the frontier is expanding rapidly to include everything from automated audio ad creation to dynamic, personalized visuals for social media. The rise of short-form AI video platforms and other multimedia formats places new demands on inference infrastructure, requiring engines that can handle diverse and complex workloads efficiently. This trend makes versatile LLM deployment 2025 strategies essential.
The Unwavering Importance of Data Privacy and Compliance
Consumer awareness and stringent regulations like the California Consumer Privacy Act (CCPA) have placed data privacy at the forefront. Marketers cannot afford a misstep. The ability to deploy AI inference engines on-premise or within a secure virtual private cloud (VPC) is a critical feature. This control ensures data privacy compliance with generative AI tools in the USA, protecting sensitive customer information and building the trust that is foundational to brand loyalty.
A Deep Dive into the Top 6 LLM Inference Engines for Marketers
Each of the top-tier AI inference engines offers a unique combination of strengths tailored to specific marketing challenges. Understanding these nuances is key to making the right investment.
1. vLLM: The High-Throughput Engine for E-commerce Personalization
For high-traffic e-commerce sites and platforms focused on omnichannel personalization AI, vLLM has emerged as a game-changer. Its primary innovation is PagedAttention, a memory management algorithm inspired by virtual memory in operating systems.
Technical Advantage: PagedAttention and Continuous Batching
PagedAttention eliminates massive amounts of wasted memory by managing attention keys and values in non-contiguous blocks. Paired with continuous batching, it allows vLLM to process far more requests in parallel on the same GPU, dramatically increasing throughput and driving down the cost per user.
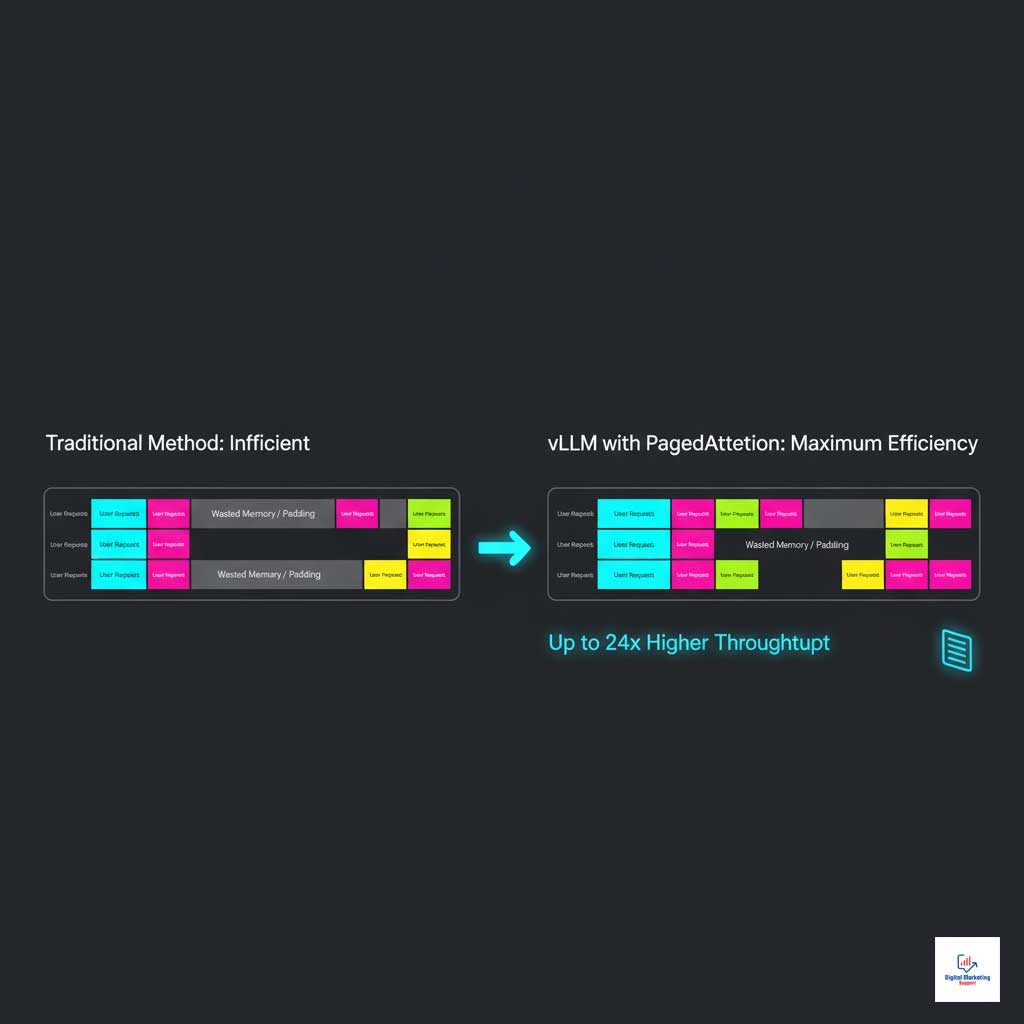
Key Marketing Application: E-commerce and Content Platforms
This high throughput is perfect for hyper-personalized marketing. It means an e-commerce site can serve real-time, individually tailored product recommendations to millions of concurrent users without crippling server costs, directly impacting conversion rates and average order value.
Strategic Implementation
A large online retailer could use vLLM to power its entire personalization stack. This includes dynamically changing the homepage for every visitor, customizing search results based on browsing history, and generating personalized “you might also like” sections, all with minimal latency.
2. NVIDIA TensorRT-LLM: The Low-Latency Choice for Programmatic Ad Tech
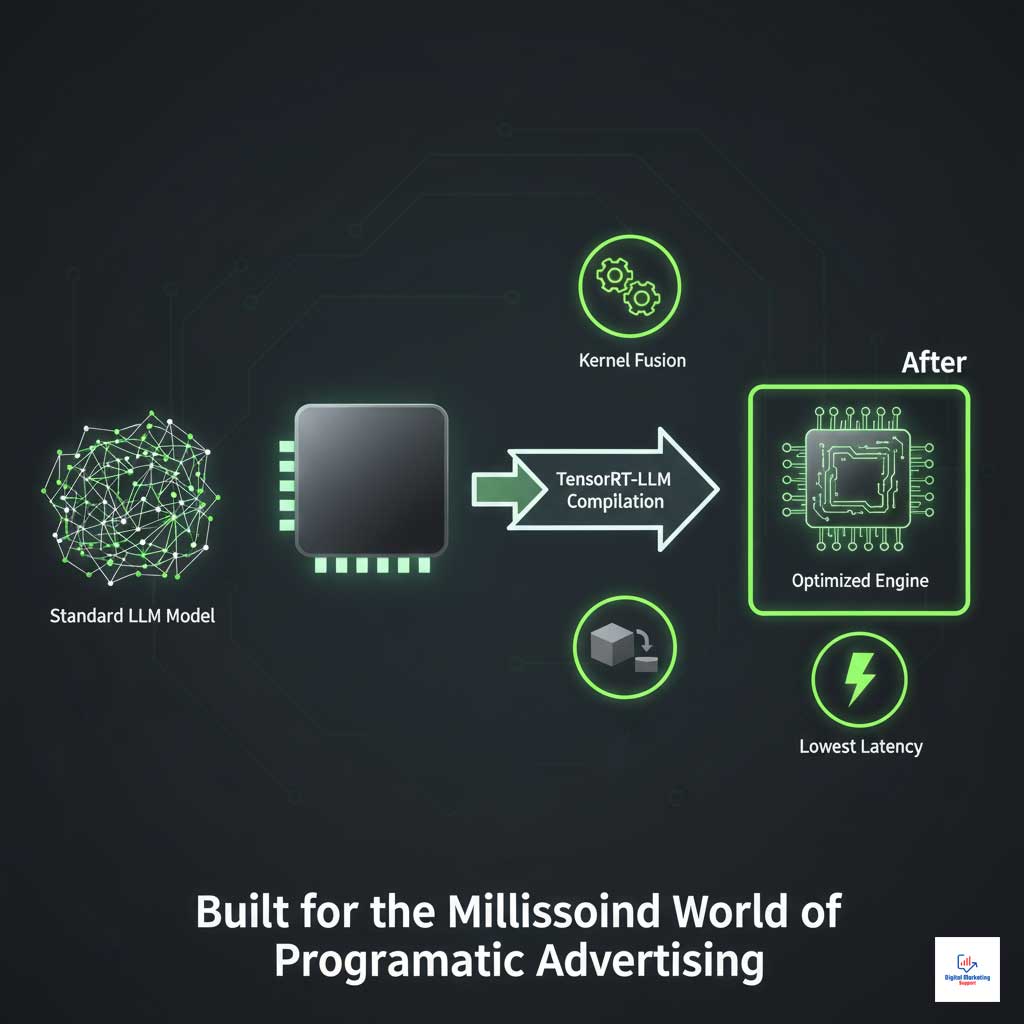
In the world of programmatic ad tech, decisions are made in milliseconds. NVIDIA’s TensorRT-LLM is built for this high-stakes environment. It is an open-source library that compiles LLMs into highly optimized runtime engines specifically for NVIDIA GPUs.
Technical Advantage: Model Compilation and Kernel Fusion
TensorRT-LLM takes a standard LLM and rebuilds it for maximum speed. It uses techniques like kernel fusion to combine multiple computational steps into one, drastically reducing overhead. This results in the lowest possible latency, a critical factor in any AI for digital advertising application.
Key Marketing Application: Real-Time Bidding (RTB)
Its primary use case is powering real-time bidding algorithms. The engine’s speed allows an ad exchange to analyze more data points about the user and the ad placement before making a bid, leading to more intelligent ad spend and better campaign outcomes.
Strategic Implementation
A media agency can integrate TensorRT-LLM into its demand-side platform (DSP). This would enable their AI marketing automation tools to make more sophisticated, AI-driven bid decisions in under 100 milliseconds, outperforming competitors and optimizing ad spend for clients.
3. Hugging Face Text Generation Inference (TGI): The Go-To for Scalable Conversational AI
Hugging Face TGI is a production-ready, open-source solution that has become an industry standard for large language model serving. Its versatility and robust feature set make it a top choice for powering interactive applications.
Technical Advantage: Production-Ready and Versatile
TGI supports a vast range of popular open-source models out of the box. It incorporates key performance features like continuous batching and token streaming, which are essential for creating a smooth, responsive user experience in AI chatbots for customer experience.
Key Marketing Application: Customer Service and Engagement
TGI is ideal for deploying advanced AI chatbots and virtual assistants. These bots can handle complex customer queries, provide personalized support, guide users through sales funnels, and enhance overall user engagement on a website or app.
Strategic Implementation
A U.S.-based SaaS company can use TGI to deploy a sophisticated support bot that not only answers FAQs but also integrates with their backend to check account statuses, troubleshoot technical issues, and intelligently escalate complex problems to human agents.
4. LMDeploy: The Efficiency Champion for AI-Driven Content Creation
LMDeploy is a powerful toolkit focused on making LLM deployment 2025 more efficient and accessible. Its standout feature is its state-of-the-art support for quantization, a technique that reduces the model’s size without a significant drop in quality.
Technical Advantage: Advanced Quantization
LMDeploy allows marketers to run powerful models using 4-bit quantization (W4A16), which dramatically reduces the memory footprint and computational requirements. This can make inference up to 2.4 times faster than standard 16-bit precision, enabling high-performance AI-driven content creation on more affordable hardware.
Key Marketing Application: Content Generation at Scale
This efficiency makes it perfect for marketing campaign automation with AI engines. It allows marketing teams to automate the generation of thousands of personalized emails, social media posts, product descriptions, and blog drafts without needing top-of-the-line, expensive GPUs.
Strategic Implementation
A digital marketing agency can build a proprietary content generation service for its clients using LMDeploy. This would allow them to offer highly scalable and cost-effective AI-driven content creation services, giving them a competitive edge.
5. SGLang: The Specialist for Complex, Multi-Step Marketing Interactions
While many engines focus on simple prompt-to-response tasks, SGLang is designed to excel at complex, multi-stage LLM interactions. It is engineered for scenarios where the AI needs to reason, use external tools, and manage intricate control flows.
Technical Advantage: RadixAttention for Complex Prompts
SGLang’s core innovation, RadixAttention, is highly efficient at managing and reusing computations across complex generation flows (e.g., chain-of-thought prompting or interacting with APIs). This results in significant speedups for multi-step AI tasks common in augmented analytics.
Key Marketing Application: Advanced AI Agents and Analytics
SGLang is the ideal engine for building sophisticated AI agents. These agents can perform complex tasks like analyzing sales data, identifying trends, and then automatically drafting a strategic response—all within a single, coherent workflow.
Strategic Implementation
A large retailer can use SGLang to power an AI analytics agent. A marketing manager could ask, “Summarize last week’s sales from our loyalty program members in the Northeast, identify the top 3 selling products, and draft a targeted email campaign for that segment,” and the SGLang-powered agent could execute the entire chain of tasks.
6. DeepSpeed Inference: The Powerhouse for Enterprise-Scale Audience Segmentation
Born from Microsoft’s research, DeepSpeed Inference is built to handle the largest and most demanding models on the planet. It is the go-to solution for enterprises that need to perform deep analysis on massive, proprietary datasets.
Technical Advantage: Multi-GPU Parallelism
DeepSpeed excels at various forms of parallelism (tensor, pipeline), which allows it to split a single massive LLM across multiple GPUs. This makes it possible to run models with hundreds of billions of parameters that would be too large for any single device.
Key Marketing Application: Deep Audience Segmentation
Its ability to handle enormous models makes it perfect for large-scale data analysis. An enterprise can use a DeepSpeed-powered model to analyze its entire customer database, uncovering subtle patterns and creating hyper-granular audience segments for highly targeted campaigns.
Strategic Implementation
A Fortune 500 financial services company can use DeepSpeed Inference to analyze petabytes of transactional and behavioral data. The goal would be to identify nuanced customer segments for new product offerings, enabling a level of targeting that goes far beyond traditional demographic segmentation.
Comparative Analysis: Choosing the Right Inference Engine for Your Marketing Goals
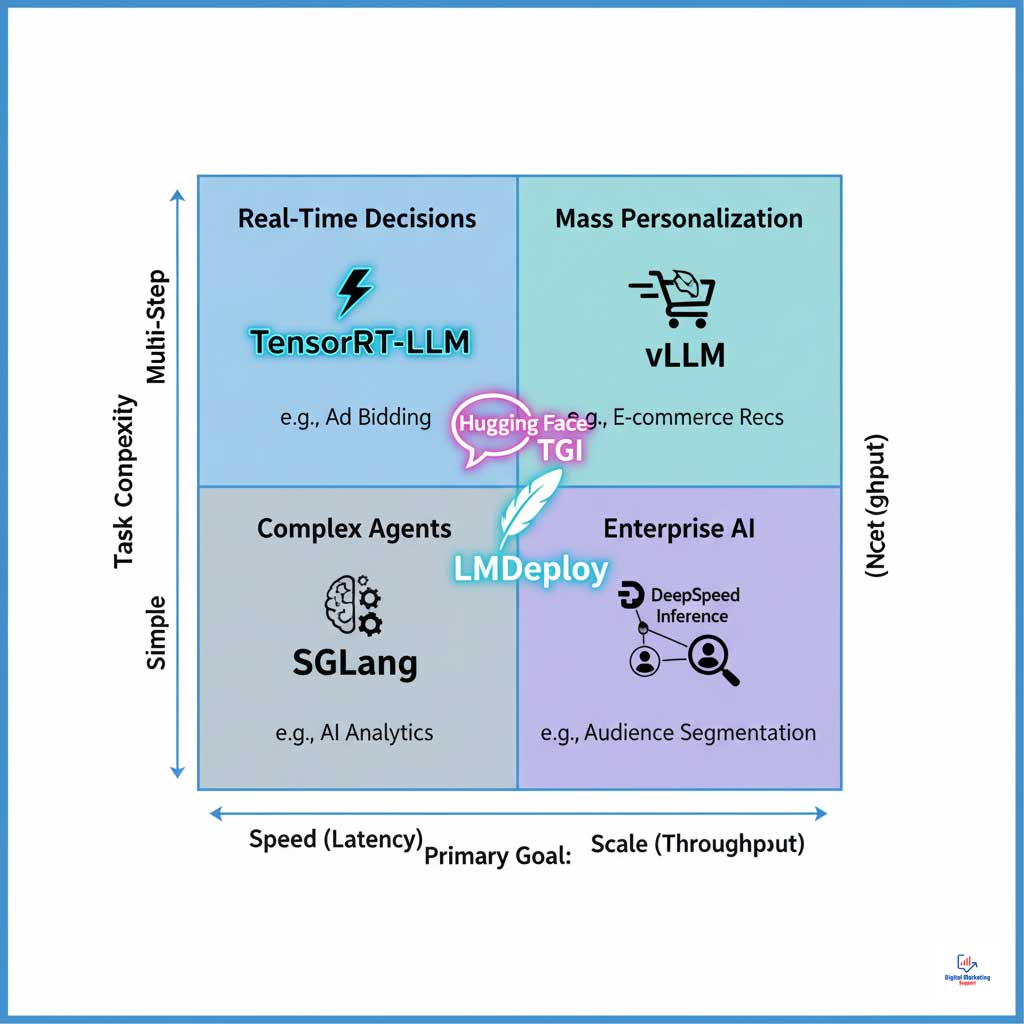
Selecting the right engine requires a clear understanding of your primary marketing objective. The table below provides a scannable comparison to guide your decision-making process. It is a critical tool for any team building out their AI inference engines strategy.
| Inference Engine | Primary Marketing Use Case | Key Technical Advantage | Best for Throughput | Best for Latency | Cost-Effectiveness |
| vLLM | E-commerce Personalization | PagedAttention | ★★★★★ | ★★★☆☆ | ★★★★★ |
| TensorRT-LLM | Programmatic Ad Bidding | Model Compilation & Optimization | ★★★☆☆ | ★★★★★ | ★★★★☆ |
| Hugging Face TGI | Conversational AI / Chatbots | Production-Ready & Versatile | ★★★★☆ | ★★★☆☆ | ★★★★☆ |
| LMDeploy | AI Content Generation | Quantization & Efficiency | ★★★★☆ | ★★★★☆ | ★★★★★ |
| SGLang | Complex AI Agents / Analytics | RadixAttention (Complex Prompts) | ★★★☆☆ | ★★★★☆ | ★★★☆☆ |
| DeepSpeed Inference | Large-Scale Data Segmentation | Multi-GPU Parallelism | ★★★☆☆ | ★★★☆☆ | ★★☆☆☆ |
Use Case to Engine Mapping: A Practical Guide for Marketers
To further simplify the selection process, this table maps common marketing tasks directly to the most suitable AI inference engines, providing clear justifications for each recommendation.
| Marketing Task / Goal | Primary Recommended Engine | Secondary Option | Why? |
| Real-Time Ad Bidding & Optimization | TensorRT-LLM | LMDeploy | Requires the absolute lowest latency for split-second decisions in programmatic ad tech. |
| Hyper-Personalization on a High-Traffic Website | vLLM | Hugging Face TGI | Needs to serve millions of users simultaneously with high throughput for omnichannel personalization AI. |
| Advanced Customer Support Chatbot | Hugging Face TGI | SGLang | Offers a stable, versatile platform for building great AI chatbots for customer experience. |
| Automating 10,000+ Personalized Emails | LMDeploy | vLLM | Efficiency and speed in AI-driven content creation are paramount for cost-effective scaling. |
| AI Agent for Multi-Channel Campaign Automation | SGLang | Hugging Face TGI | Excels at complex, multi-step tasks involving reasoning and tool use. |
| Deep Audience Segmentation on Terabytes of Data | DeepSpeed Inference | N/A | Specifically designed to handle models large enough for this enterprise-level task. |
Summary & Key Takeaways: Building Your Future-Proof AI Marketing Stack
The era of one-size-fits-all marketing is definitively over. In 2025, success is defined by the ability to deliver personalized, relevant, and timely experiences at scale, all while navigating a complex economic and regulatory environment. The six AI inference engines detailed above represent the cutting edge of large language model serving and are the foundational pillars of modern marketing.
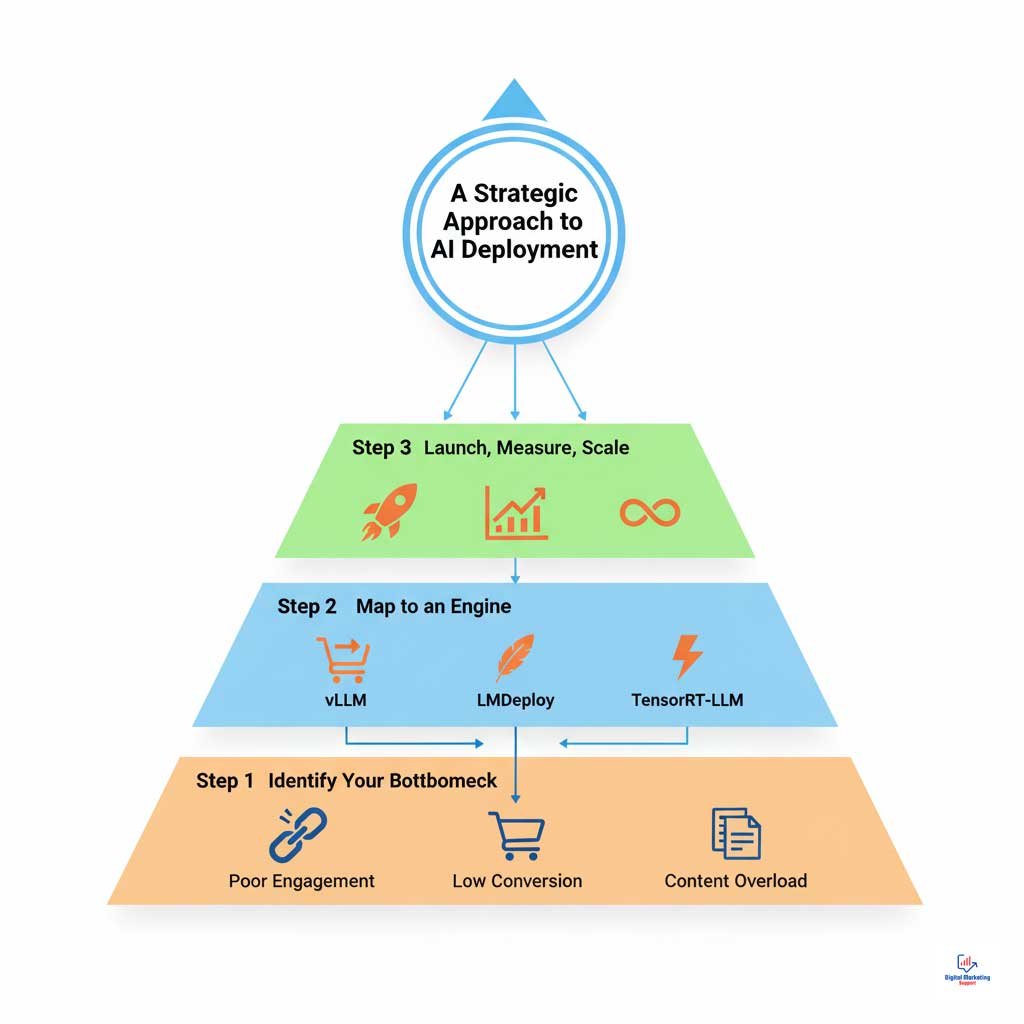
Making the right choice is a strategic decision that directly impacts profitability and competitive advantage. The best engine is not a universal choice but depends entirely on your primary goal—latency for speed, throughput for scale, or efficiency for cost. By starting with a pilot project focused on your biggest marketing bottleneck and using the frameworks in this article, you can build a powerful, efficient, and future-proof AI stack that drives real business results.
Frequently Asked Questions (FAQ)
What are the best inference engines for AI-powered marketing in 2025?
The best engine depends on your goal. For high-volume e-commerce personalization, vLLM is a top choice. For ultra-low-latency programmatic advertising, TensorRT-LLM excels. For versatile chatbots and content creation, Hugging Face TGI and LMDeploy are excellent, cost-effective options.
How do digital marketers in the U.S. benefit from LLM serving platforms?
They allow marketers to automate personalized content creation at scale, optimize ad spend in real-time, deliver superior customer experiences through intelligent chatbots, and gain deeper insights from their first-party data, all of which lead to higher engagement and ROI.
How is the global economy affecting AI adoption in digital advertising?
Economic pressures are accelerating the adoption of efficient AI solutions. Marketers are prioritizing cost-effective AI inference engines like vLLM and LMDeploy that maximize GPU utilization to control operational costs while still scaling their AI-driven campaigns.
Which AI inference engine is most cost-effective for scaling campaigns?
For most large-scale campaigns requiring high throughput, vLLM is often considered the most cost-effective due to its PagedAttention technology, which significantly improves GPU efficiency and allows you to serve more users with the same hardware.
How do you select the right AI engine for your marketing needs?
Start by identifying your primary business objective. If it’s real-time ad bidding, prioritize low-latency engines like TensorRT-LLM. If it’s personalizing content for millions of users, choose a high-throughput engine like vLLM. For content creation on a budget, look to an efficient engine like LMDeploy.
Are there real examples of U.S. brands improving ROI with LLM tools?
Absolutely. Major U.S. retailers are using these engines to power recommendation systems that have significantly boosted conversion rates. B2B companies are using AI-driven content creation to scale lead generation, and media agencies are using real-time AI to optimize ad spend for better performance.
What is the difference between throughput and latency in LLM serving?
Latency is the time it takes to get a single response (speed). Throughput is the number of responses the system can handle in a period (capacity). For real-time bidding, low latency is critical. For personalizing a website for millions of users at once, high throughput is the key metric.
Can I run these inference engines on the cloud, or do I need my own servers?
All of these engines are flexible. They can be deployed on major cloud providers like AWS, Google Cloud, and Azure, or on your own on-premise servers. This allows businesses to choose a deployment strategy that best fits their needs for performance, cost, and data security.
What is quantization and why is it important for marketing budgets?
Quantization is a technique that reduces the size of an AI model by using less precise numbers to represent its weights. Engines like LMDeploy use it to make models run faster and consume less memory, which allows marketers to deploy powerful AI on more affordable hardware, directly reducing infrastructure costs.
What’s the next big trend in LLM deployment for marketers beyond 2025?
The next trend is likely the rise of multi-modal AI agents. These will be AI systems that can not only understand text but also see images, watch videos, and hear audio, then take complex actions across multiple marketing platforms. Serving these advanced models will require even more sophisticated and specialized AI inference engines.